2. Prototypen für die computergestütze Filmanalyse
In diesem Abschnitt werden drei unterschiedliche Prototypen beschrieben, die jeweils auf unterschiedliche quantifizierbare Aspekte von Filmen abzielen und damit die Untersuchung ganz unterschiedlicher Fragestellungen erlauben. Die Tools greifen allesamt auf im Web frei verfügbare Informationen zu Filmen zurück: So stehen etwa über die Plattformen OpenSubtitles oder die Internet Script Movie Database maschinenlesbare Dialoge von Filmen und Serien in großem Umfang zur Verfügung. Zusätzlich können detaillierte Metadaten sowie auch nutzergenerierte Bewertungen und Kommentare zu Filmen über Plattformen wie IMDb (Internet Movie Database) abgerufen werden. Darüber hinaus soll als weiterer quantifizierbarer Parameter, der direkt aus den Filmen extrahiert werden kann, die Farbverwendung 2 in die Analysen mit einbezogen werden. Alle nachfolgend beschriebenen Prototypen wurden jeweils mit Standard-Webtechnologien (HTML / CSS / JavaScript) und bestehenden Python-Bibliotheken umgesetzt.
2.1. SubVis – Analyse der Filmsprache
Das SubVis-Tool analysiert über OpenSubtitles verfügbare Dialoge von beliebigen, zunächst allerdings nur englischsprachigen Filmen anhand typischer linguistischer Parameter wie Wortfrequenzen oder POS-Tagging und visualisiert die Ergebnisse in einem interaktiven Web-Interface. Zusätzlich kann die Auftretenshäufigkeit einzelner Zeichen oder längerer Sprachsequenzen (= jeweils ein eingeblendeten Untertitel) für beliebig definierbare Analyseintervalle (z. B. jeweils für 5 Minuten-Sequenzen) in einer Timeline dargestellt werden, um bspw. auf einen Blick zu sehen, an welchen Stellen im Film besonders viel oder wenig gesprochen wird (vgl. Abbildung 1).
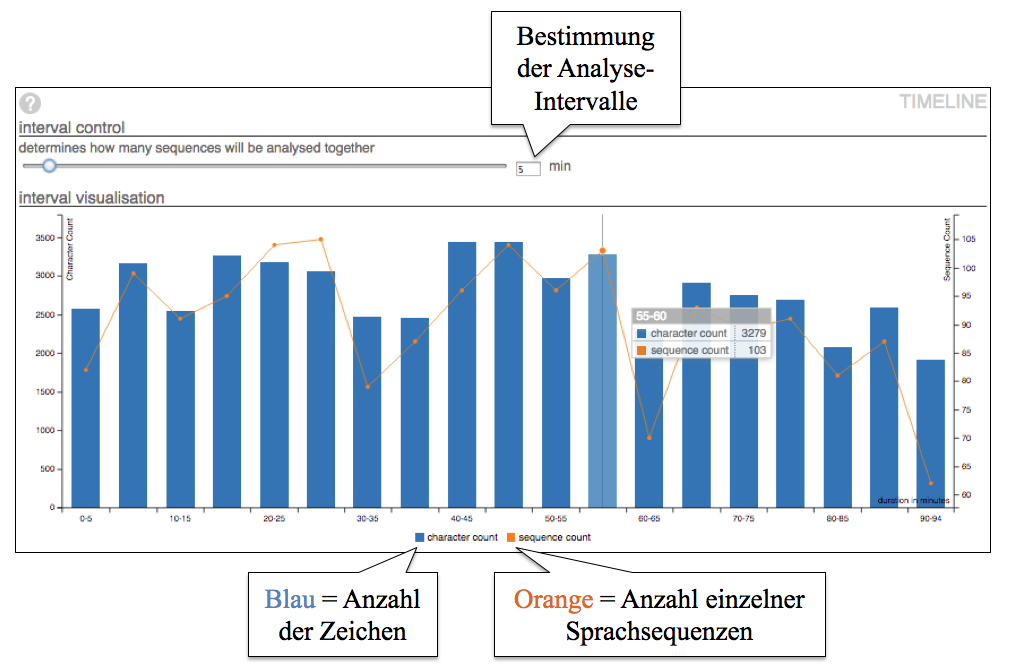
Beispielhafte Fragestellungen, die mit dem Tool untersucht werden können:
- Gibt es für die Filme unterschiedlicher Regisseure jeweils typische Schlüsselwörter?
- Kann man für Filme aus unterschiedlichen Genres beobachten, dass an bestimmten Stellen (z. B. Anfang oder Schluss) besonders viel oder wenig gesprochen wird?
- Wird in Filmen aus den 1980er Jahren insgesamt mehr gesprochen als in Filmen der 1990er Jahre?
2.2. Series Analysis Tool (SAT) – Analyse von TV-Serien anhand von Nutzerbewertungen, Figuren und Sprache
Das Series Analysis Tool ( SAT) ermöglicht die Analyse von Serien und einzelnen Episoden. Dabei werden verschiedene Parameter in einer Timeline-Darstellung visualisiert. Ein wesentlicher Analyseaspekt ist dabei die Bewertung einzelner Episoden durch die IMDb-Community, sodass auf einen Blick erkennbar ist, ob eine Serie im Laufe der Zeit besser oder schlechter bewertet wird, oder ob es einzelne Episoden gibt, die auffallend positiv oder negativ bewertet wurden. Zusätzlich liest das Tool das Figureninventar für jede Episode aus und erlaubt es, die Darstellung nach bestimmten Figuren zu filtern. So kann schnell erkannt werden, ob das Auftreten bestimmter Figuren ggf. Einfluss auf die Bewertung einzelner Episoden hat. Weiterhin wurde die Sprache der Serien hinsichtlich Sentiment- und Emotionswörtern analysiert (vgl. Abbildung 2). Als Datengrundlage dient ein bestehendes Korpus (Tiedemann 2012), in dem alle auf OpenSubtitles in englischer Sprache verfügbaren Untertitel von TV-Serien und Filmen bis zum Jahr 2013 enthalten sind. Dabei kam für die Sentiment Analyse das AFINN-Lexikon (Nielsen 2011) und für die Identifikation acht grundlegender Emotionen (Angst, Wut, Freude, etc.) das NRC Emotion Lexicon (Mohammad / Turney 2010) zum Einsatz. Sowohl die Sentiment-Scores (positiv / negativ) als auch die Emotionsmarker können für jede Episode in die Visualisierung mit einbezogen werden, um so potenzielle Korrelationen zu den Nutzerbewertungen aufzuzeigen.
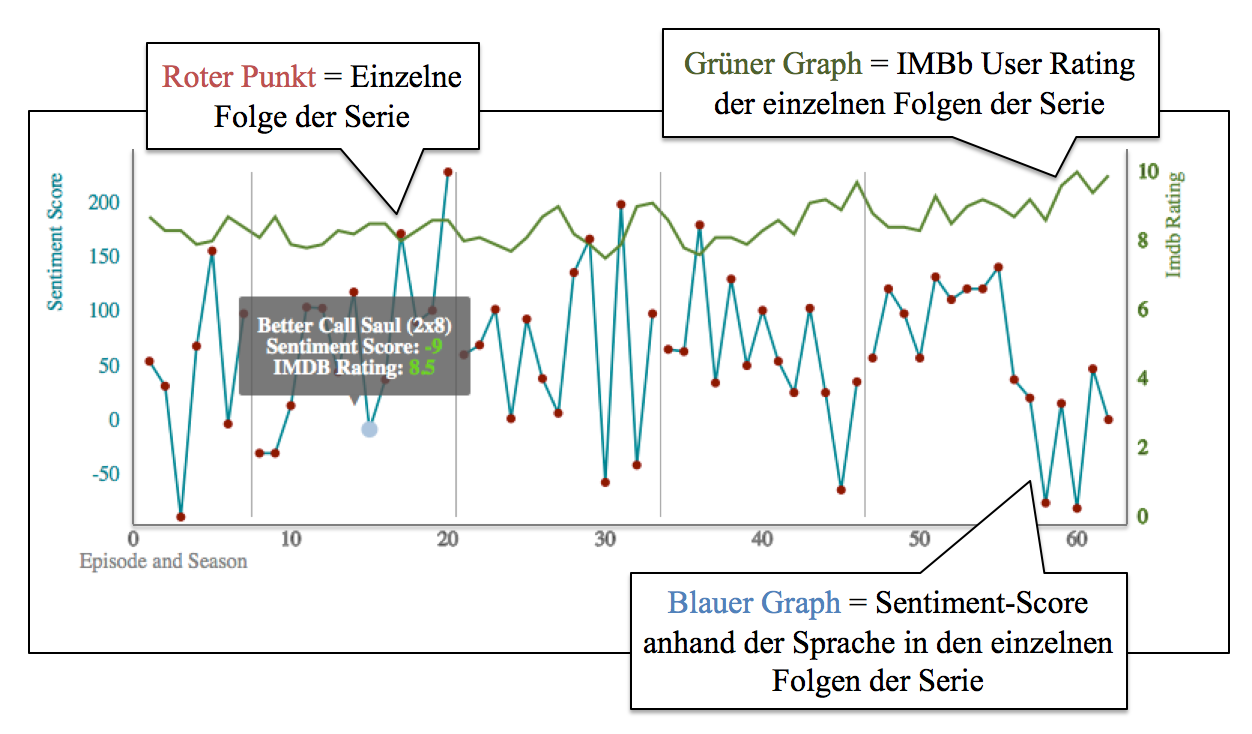
Beispielhafte Fragestellungen, die mit dem Tool untersucht werden können:
- Gibt es generelle Trends bei der Bewertung von Serien mit zunehmender Zahl von Staffeln?
- Wirken sich Sentiment- und Emotionsmarker der Dialoge positiv oder negativ auf die Bewertung einer Episode aus?
- Wirkt sich das Auftreten bestimmter Nebenfiguren positiv oder negativ auf die Bewertung einer Episode aus?
2.3. MovieColors – Analyse von Filmen anhand von Farbe und Sprache
Der Prototyp MovieColors erlaubt die computergestützte Analyse von Filmen anhand der Parameter Farbe und Sprache. Dabei wird zunächst der Film in einzelne Frames zerlegt. Mithilfe eines Clustering-Algorithmus werden dann die jeweils dominanten Farben extrahiert. Anhand dieser Farbinformation können charakteristische Farbprofile – ähnlich wie im eingangs erwähnten MovieBarcodes-Projekt – für den gesamten Film erstellt werden. Zusätzlich wird die Sprache des Films über dessen Untertitel anhand von Wortfrequenzen und grundlegenden Sentiment-Werten (positiv / negativ) analysiert.
Die Visualisierungskomponente des Tools erlaubt es, Farbinformation und Sprachanalyse in einer parallelen Ansicht darzustellen, um so potenzielle Korrelationen zwischen dem Sentiment der Sprache und besonders markanten Schlüsselwörtern sowie auch der Farbverwendung identifizieren zu können (vgl. Abbildung 3). Zusätzlich kann jeder Frame einzeln angezeigt werden, zusammen mit dem entsprechenden Untertitel sowie einer Analyse der dominanten Farben im jeweiligen Bild.
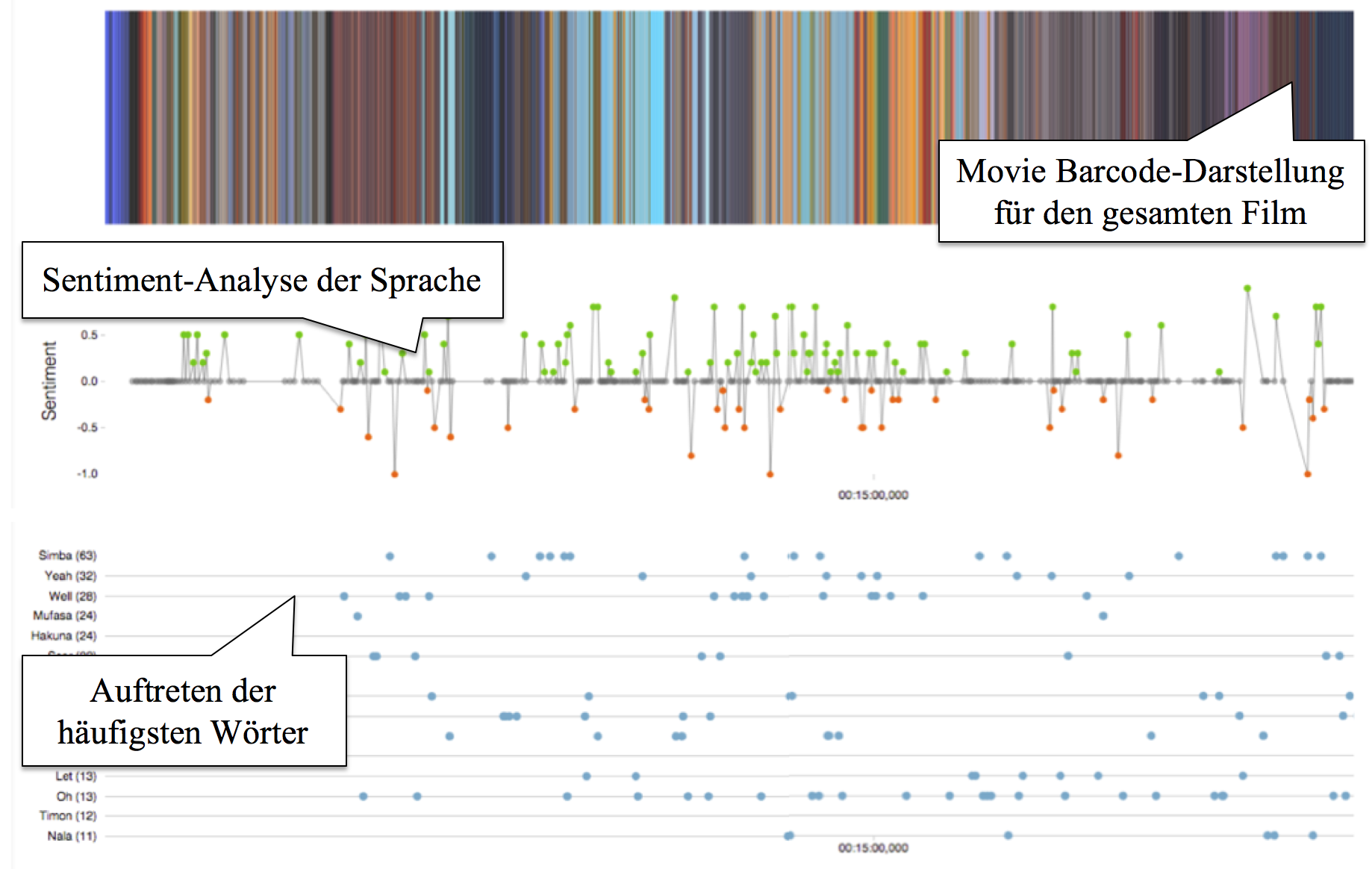
Beispielhafte Fragestellungen, die mit dem Tool untersucht werden können:
- Gibt es charakteristische Farbprofile für Filme aus verschiedenen Genres oder Epochen?
- Korrelieren bestimmte Farben mit positiven oder negativen Sentiment-Scores, also etwa dunkle Farben bei negativer Sprache?
- Korrelieren bestimmte Farben mit Schlüsselwörtern, also etwa schwarz und lila immer dann, wenn der Bösewicht des Films auftritt?