3. Das Annotationstool
Die Komplexität des in Sektion 2 dargestellten Annotationstools wird zwar zum einen sehr vielfältige linguistische Anfragen und eine detaillierte Analyse der Sprache ermöglichen, andererseits jedoch verhindert ebendiese Komplexität eine automatische Annotation. Ein Vectorspace-Modell (das für maschinelle Lernverfahren benutzt werden muss) das alle morphologischen Merkmale abdecken würde, wäre zu groß. Vorstellbar ist lediglich eine flache automatische Annotation (z. B. der Wortarten); jedoch wird auch für eine solche zunächst eine relativ große Menge an Trainingsdaten benötigt. Daher ist die Entwicklung eines Werkzeugs für die manuelle Annotation ein obligatorischer Schritt.
Das eigens für das Altäthiopische entwickelte Annotationstool berücksichtigt die spezifischen Besonderheiten der Sprache, von denen einige oben in Sektion 1 kurz skizziert wurden. Aufgrund der dargestellten Eigenheiten sowohl des Silbenalphabets als auch der semitischen Morphologie kann der Text nicht unmittelbar in der Originalschrift annotiert werden. Eine Annotation kann daher ausschließlich in der Transliteration erfolgen (siehe obiges Beispiel bet-u).
Die Transliteration wiederum ist nur bedingt durch automatische Regeln beschreibbar. Phänomena wie Konsonantenverdoppelung oder Kontraktion von zwei Silben können nicht durch klare Regeln beschrieben werden. Einige solcher Phänomena ließen sich zwar mittels weiterer Ressourcen automatisch regeln (z. B. Konsonantenverdoppelung bei bestimmten Verbklassen), jedoch müssten derartige Informationen aus einem (bisher noch nicht vorhandenen) digitalen Lexikon extrahiert werden. Auch über die genannten Schwierigkeiten hinaus wäre die Entwicklung einer (semi-)automatischen Transliteration ein äußerst zeitaufwendiger Prozess. Daher haben wir uns für die folgenden Arbeitsschritte entschieden:
- Die Texte werden mittels eines automatischen regelbasierten Prozesses transkribiert.
- Die Transkription wird manuell korrigiert (entspricht der Transliteration des Textes)
Aus den oben genannten Gründen ist der in der Arbeit mit anderen Sprachen gängige Arbeitsablauf – zuerst Textkorrektur, dann Annotation – hier nicht möglich. Ein solcher ist jedoch bei bereits existierenden Tools Bedingung, wenn eine Mehrebenen-Annotation angestrebt wird. Das CorA-Tool (vg. Bollmann et al.) ermöglicht zwar Korrekturen synchron mit der Annotation, jedoch sind nicht mehr als zwei Annotationsebenen möglich; auch eine Mehrwortannotation ist nicht erlaubt. Für die Annotation muss ein XML-Schema des Tagsets vorliegen und es werden alle möglichen Kombinationen von morphologischen Merkmalen je Wortart generiert. Da sämtliche Kombinationsmöglichkeiten dem Benutzer in Form einer Dropdown-Liste präsentiert werden, ist das Tool in der Anwendung mit dem sehr umfangreichen Tagset für das Altäthiopische ungeeignet. Ein anderes Tool, das relativ häufig angewendet wird, ist WebAnno. Dieses Tool ermöglicht eine Annotation mit mehr als zwei Ebenen, jedoch sind Korrekturen im Text während der Annotation nicht möglich.
Im TraCES Projekt implementieren wir eine neuartige Architektur, die sowohl Änderungen im Text als auch eine Mehrebenen-Annotation ermöglicht.
Wir betrachten als Grundtext den Originaltext in der altäthiopischen Schrift. Die Transliteration bildet die erste und die morphologische Annotation die zweite Ebene, wobei die Transliteration und der Originaltext bei allen Arbeitsschritten synchronisiert bleiben. Im folgenden Abschnitt beschreiben wir das Datenmodell, das diese Architektur ermöglicht.
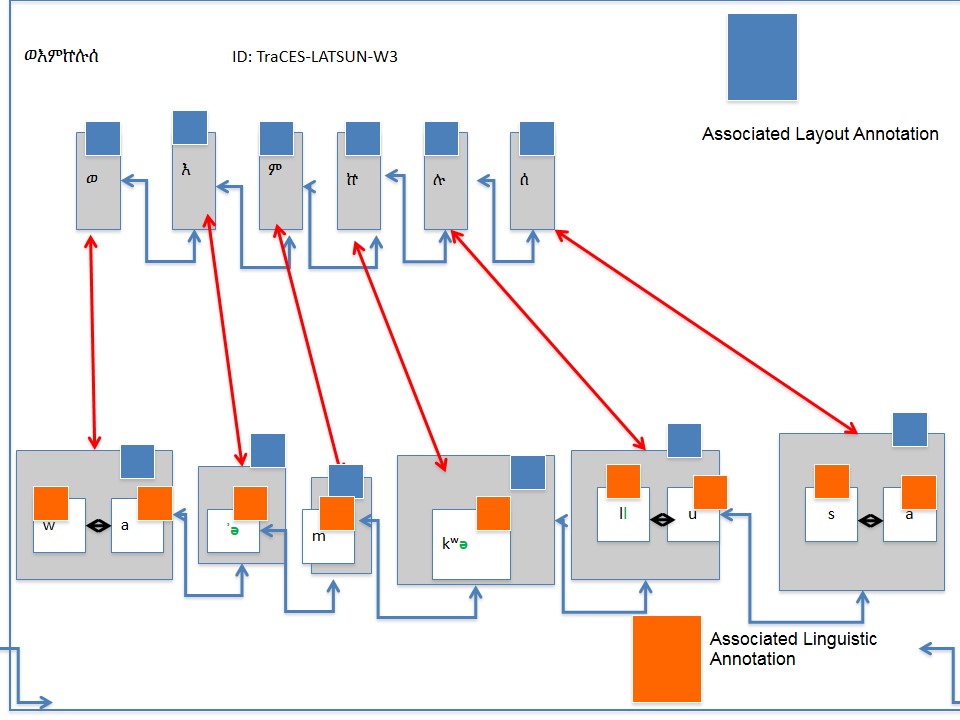
Die Basiseinheit in unserem System ist ein Wort, das eine einmalige ID zugewiesen erhält. Ein Wort hat folgende Komponenten:
- Eine Liste der einzelnen Fidal 1-Objekte, wo ein Fidal-Objekt aus einer ID und einem Label (dem Fidal-Buchstaben) besteht.
- Eine Liste einzelner Silben-Objekte, wo ein Silben-Objekt aus einer ID und einer Liste von einzelnen Buchstaben-Objekten besteht
- Ein Buchstaben-Objekt hat immer eine ID und ein Label (das graphische Symbol)
Die Zusammengehörigkeit aller Komponenten wird durch die ID-Zusammensetzung gesichert:
Eine Wort ID ist aus vier Komponenten zusammengesetzt
Projekt ID + Dokument ID + W + automatisch generierte Random ID
Ein Fidal-Buchstaben-Objekt wird dann durch
Wort ID + F + Random-Nummer
identifiziert, während ein Transliterationssilben-Objekt:
Wort ID + TF + Random-Nummer
als ID hat.
Ein Transliterationsbuchstabe wird durch:
Wort ID + Transliterationssilben ID + L + Random-Nummer
identifiziert.
Durch dieses System ist es zu jeder Zeit möglich, jeden einzelnen Buchstaben zu identifizieren und zu referenzieren. Da wir jeden Buchstaben als Objekt betrachten, trennen wir die graphische Realisierung von der linguistischen Annotation; so sind etwa die Annotation und die graphische Repräsentation eines Buchstabens in der Transliteration Labels für ein und dasselbe Objekt.
In der Abbildung 1 wird dieses Modell für die Wortgruppe ወእምኵሉሰ „ und vor allem nämlich“ (eigentlich ወ - እም - ኵሉ - ሰ, aber graphisch quasi ein „Wort“) dargestellt: