3. Umfrage
Die Umfrage wurde in Kooperation der drei Projektpartner zunächst mit 10 Testnutzern pilotiert und anschließend in ihrer endgültigen Form mit Hilfe der Software LamaPoll implementiert. Sie besteht aus insgesamt 128 Fragen, die in einen allgemeinen Teil mit Fragen zu persönlichen Daten (Alter, Sprachkenntnisse etc.) und zu relevanten Vorkenntnissen (Suchsprachen, Transkriptionserfahrung etc.) sowie drei angebotsspezifische Teile zu den jeweiligen Plattformen unterteilt sind.
Ein Aufruf zur Teilnahme wurde an etwa 5000 registrierte Nutzer der drei Angebote geschickt. Die Umfrage war anschließend für einen Monat offen. 669 Nutzer folgten dem Aufruf, 401 davon füllten den Fragebogen komplett aus. Dies entspricht einer Rücklaufquote von 8%. Im Folgenden diskutieren wir exemplarisch Ergebnisse zu ausgewählten Teilen der Umfrage.
3.1. Allgemeiner Teil
Nach den persönlichen Angaben im allgemeinen Teil ist der typische Nutzer eine Nutzerin (67%) zwischen 21 und 30 Jahren (54%), hat Deutsch als Muttersprache (66%), lebt und arbeitet in Deutschland (71%) und befindet sich im Studium bzw. ist graduiert (59% gegenüber 40% auf Doktorandenniveau oder darüber).
Auf die Frage „Welche Bereiche interessieren Sie?“ (Mehrfachauswahl war möglich), wurde wie folgt geantwortet:
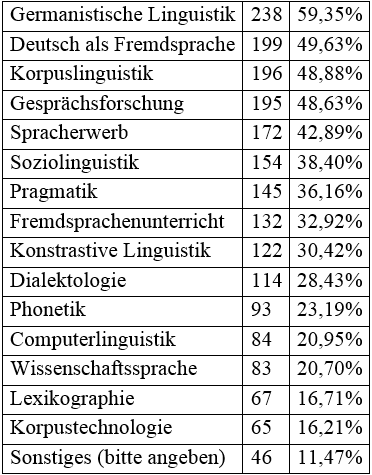
Abb. 1: Frage 6 – „Welche der folgenden Bereiche interessieren Sie? (Mehrfachantwort möglich)“
Die Antworten zeigen, dass die Interessen der Nutzer sich über das gesamte Spektrum der zur Auswahl stehenden Teildisziplinen verteilen. Keine der Optionen wurde von weniger als 10% ausgewählt, so dass wir einstweilen auch keine der betreffenden Nutzergruppen als irrelevant für die weitere Entwicklung der Angebote ausschließen können. Unter den häufiger genannten Antworten sind mit etwa DaF, Gesprächsforschung und Pragmatik mehrere Nutzergruppen, für die trotz ihrer traditionell empirischen Ausrichtung die Arbeit mit digitalen Sprachdatenbanken sicherlich noch nicht als der Normalfall gelten kann. Dediziert „technisch“ ausgerichtete Disziplinen wie Computerlinguistik und Korpustechnologie rangieren hingegen am unteren Ende der Liste.
Die Teilnehmer wurden weiterhin nach Vorkenntnissen befragt, die für die Arbeit mit mündlichen Korpora relevant sind:
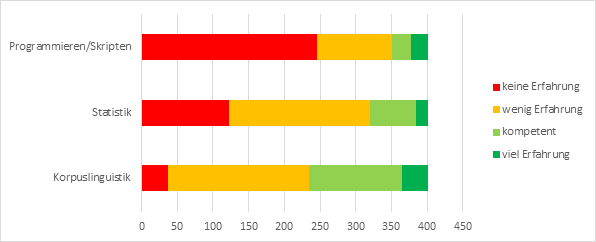
Abb. 2: Frage 10 – „Bitte beurteilen Sie Ihre Erfahrung in folgenden Bereichen“
Eine große Mehrheit der Teilnehmer gibt an, über keine oder wenig Erfahrung in Programmieren / Skripten und Statistik zu verfügen (88% bzw. 80%). Eine etwas größere Minderheit (41%) beurteilt ihre Kenntnisse in Korpuslinguistik positiv.
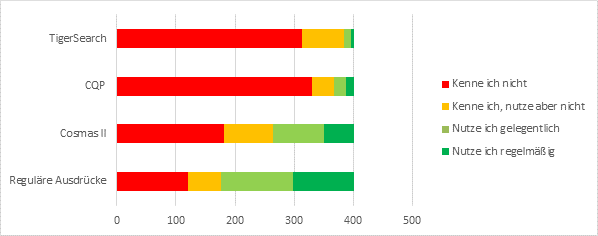
Abb. 3: Frage 11 – „Welche der folgenden Suchabfragesprachen kennen / nutzen Sie?“
Reguläre Ausdrücke sind der einzige formale Mechanismus, der von einer Mehrheit (56%) gelegentlich oder regelmäßig genutzt wird. Während COSMAS II – die Suchabfragesprache für die schriftlichen IDS-Korpora – noch bei 34% gelegentliche oder regelmäßige Anwendung findet, sind CQP und TigerSearch – als zwei weitere für die deutschsprachige Korpuslinguistik relevante Suchabfragesprachen den meisten Teilnehmern (82% bzw. 78%) unbekannt.
In Bezug auf die Vorerfahrungen mit Transkription stellt sich das Gesamtbild deutlich anders dar.
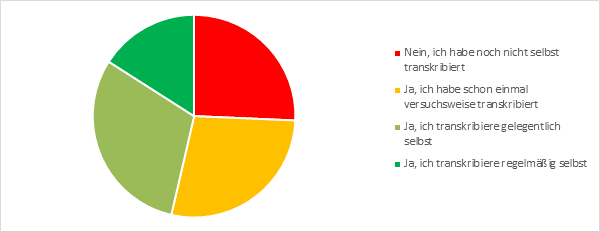
Abb. 4: Frage 13 – „Verfügen Sie über eigene Transkriptionserfahrung?“
Knapp die Hälfte der Befragten (46%) transkribiert gelegentlich oder regelmäßig selbst. Unter diesen Teilnehmern gaben etwas mehr als die Hälfte (56%) an, Standard-Office-Software (typischerweise MS Word, 82%) für die Transkription zu nutzen, etwa ebenso viele (55%), mit spezialisierter Transkriptionssoftware zu arbeiten.
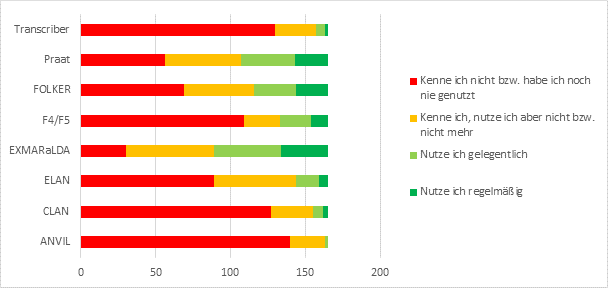
Abb. 5: Frage 16 – „Mit welchem / en spezialisierten Transkriptionseditor / en arbeiten Sie?“
EXMARaLDA (regelmäßige Nutzung: 19%, gelegentlich: 27%), Praat (13% bzw. 22%) und FOLKER (13% bzw. 17%) sind bei letzteren die am häufigsten genutzten Tools.
3.2. Angebotsspezifischer Teil
Nach dem allgemeinen Teil wurde Nutzern die Wahl gelassen, zu welchen der drei Angebote sie im weiteren Verlauf der Umfrage befragt werden wollten. Da sich eine Mehrzahl (261 Teilnehmer) hier für die DGD entschied, stellen wir im Folgenden einige exemplarische Auswertungen für diesen Teil der Umfrage vor.
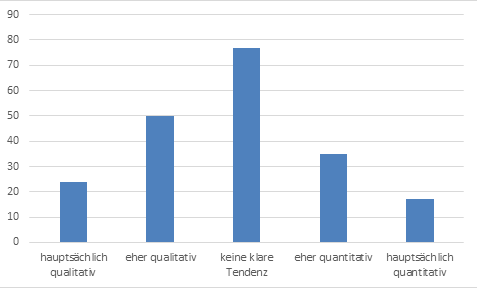
Abb. 6: Frage 33 – „Wie lässt sich Ihre methodische Herangehensweise am besten beschreiben, wenn Sie mit der Datenbank für gesprochenes Deutsch (DGD) arbeiten?“
Bei der Frage nach der Anwendung von qualitativen oder quantitativen Analysemethoden positionierte sich der größte Anteil der Befragten (38%) in der Mitte des Spektrums. Bei den übrigen Befragten zeigte sich eine leichte Tendenz zu qualitativen Herangehensweisen (37% vs. 25%).
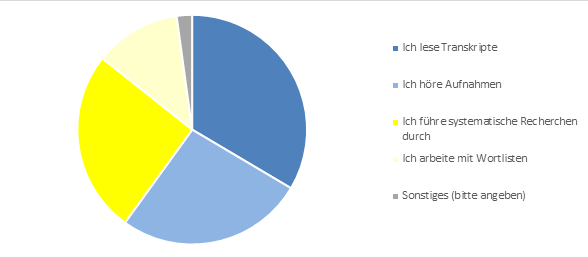
Abb. 7: Frage 34 – „Was ist Ihre Haupttätigkeit, wenn Sie mit der Datenbank für gesprochenes Deutsch (DGD) arbeiten? (Mehrfachantwort möglich)“
Dies spiegelt sich auch in den Antworten auf die Frage nach der Hauptaktivität beim Arbeiten mit der DGD wieder: Hier beurteilten die Befragten die manuell-intellektuelle Inspektion der Daten (Transkripte lesen, Audio anhören) als geringfügig relevanter als Methoden, die auf semi-automatischem Retrieval basieren (Queries, Wortlisten).
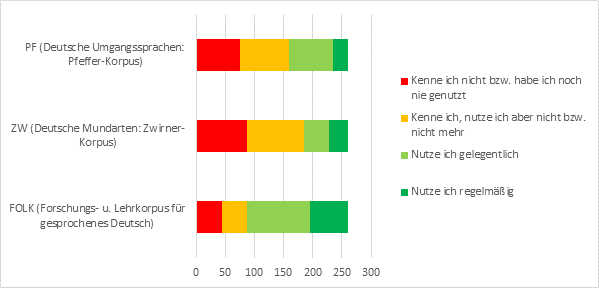
Abb. 8: Frage 37 – „Mit welchen Korpora der DGD arbeiten Sie? (Mehrfachantwort möglich)“
FOLK als das neueste, technisch fortschrittlichste und größte Gesprächskorpus ist auch dasjenige, das am meisten genutzt wird (regelmäßig oder gelegentlich von 25% bzw. 41%), und es besteht auch weiterhin Interesse an den älteren großen Variationskorpora ZW (12%/16%) und PF (10%/12%). Andere in der DGD enthaltene ältere und / oder kleinere Korpora fallen hingegen im Vergleich kaum ins Gewicht.
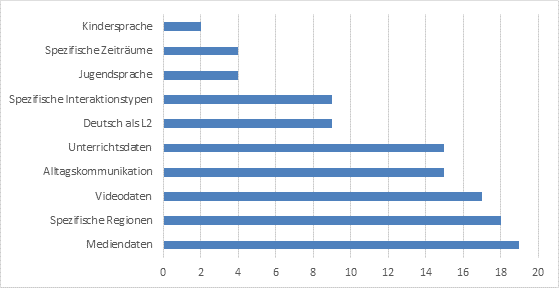
Abb. 9: Frage 54 – „Welche anderen / zusätzlichen Datentypen würden Sie sich in der DGD wünschen?“
Bei der Frage nach Wünschen für zusätzliche Daten oder neue Datentypen in der DGD wurden Mediendaten ( z. B. geskriptete oder freie Interaktionen in Fernsehen oder Radio), Videodaten und Unterrichtsdaten auffällig häufig genannt, es gab aber auch mehrfache Nutzerwünsche nach ganz spezifischen Interaktionstypen (z. B. Arzt-Patienten-Kommunikation, Konflikte), nach Daten aus bestimmten Regionen (z. B. Schweiz, ehemalige DDR, Norddeutschland) oder von bestimmten Sprechern (Kinder, Jugendliche oder L2-Lerner) sowie nach Daten aus spezifischen Zeiträumen („nach der Wende“, „die frühesten archivierten Aufnahmen“).
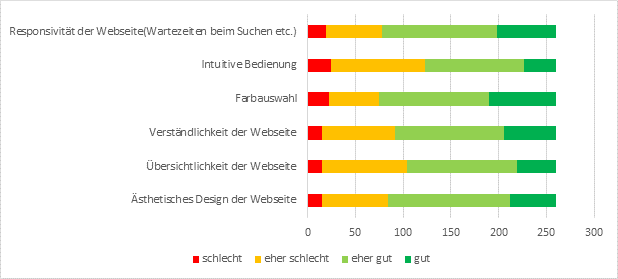
Abb. 10: Frage 52 – „Bitte bewerten Sie die Webseite der DGD“
Das Gesamturteil zur Nutzerfreundlichkeit der DGD-Website fällt positiv aus, wobei die Zufriedenheitswerte allerdings bei eher oberflächlichen Design-Details wie der Farbauswahl (positiv bewertet von über 70%) höher ausfallen als bei letztendlich entscheidenderen Kategorien wie „Intuitive Bedienung“ (52%).
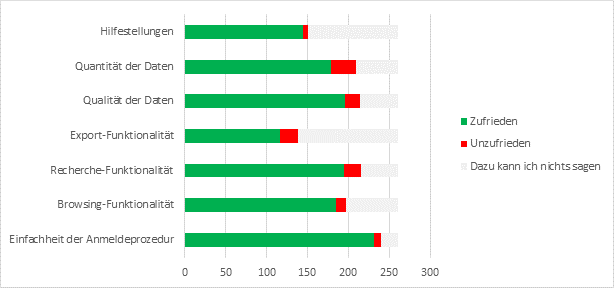
Abb. 11: Frage 49 – „Wie zufrieden sind Sie mit ...?“
Bezogen auf spezifische Teilbereiche der DGD-Funktionalität, wurden Quantität der Daten (11%), Exportoptionen (8%) und Suchfunktionalität (8%) am häufigsten als Bereiche genannt, mit denen Nutzer unzufrieden waren.