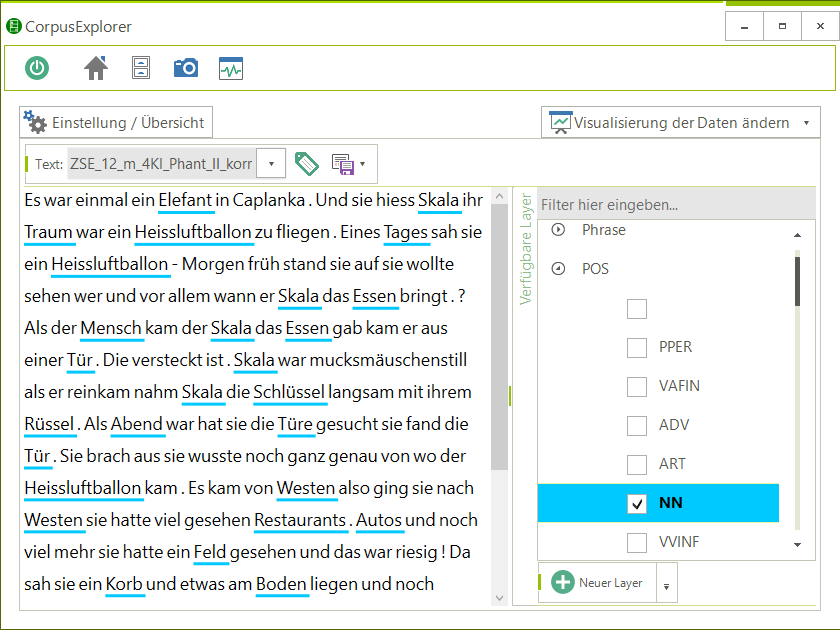
 Annotationsansicht
Annotationsansicht
Der Vortrag fußt auf drei Säulen: Theorie, Forschungspraxis und Hochschullehre. Sie werden im Vortrag einzeln ausgeführt, dann kombiniert.
Theorie: Korpuslinguistik mit Hermeneutik zu verbinden, ist keine grundsätzlich neue Idee. Die bisherigen Vorschläge (z. B. Haß 2007; Teubert 2006) führen aber in ihrer Konsequenz zu einer einseitig gelagerten Korpuslinguistik, die entweder corpus-driven oder corpus-based orientiert ist.
Bei Haß (2007) werden wichtige Grundüberlegungen der Korpus-Hermeneutik diskutiert. Im Abschnitt Haß (2007: 248-258) erfolgt eine Beispielanalyse, deren Methoden fast ausschließlich dem corpus-driven Spektrum zuzuordnen sind. Ermittelte statistische Werte werden zwar interpretiert, jedoch führt dies nicht zu weiteren Forschungskonsequenzen. Gerade aber in der zyklischen Interpretation liegt die Stärke der Korpushermeneutik.
Bei Teubert (2006) ist der Blick auf den Sichtbereich des corpus-based Methodenapperats beschränkt. Korpusmaterial dient in dieser Arbeit als eine Art Steinbruch, in dem man nach Belegen schürft. Text-Mining ist zwar ein Aspekt der Korpushermeneutik – es darf aber nie das alleinige Merkmal sein.
Daher plädiere ich für grundlegend neue und praktikable Korpushermeneutik, die sowohl klassische als auch computergestützte Analyseverfahren vereint. Einen zentralen Punkt nimmt dabei die (Weiter-)Entwicklung des bestehenden Wissens ein. Annahmen, Beobachtungen und Ergebnisse werden zu Wissensmodellen korreliert und durch einen zyklisch organisierten Analyseprozess falsifiziert. Zum jetzigen Zeitpunkt ergeben sich drei grundlegende Forderungen an eine Analyse, wenn Sie unter dem Begriff Korpushermeneutik firmieren soll:
Forschungspraxis: Gerade in den letzten fünf bis zehn Jahren ist die Möglichkeit stark gewachsen, große (linguistische) Datenmengen zu erheben und auszuwerten. Text-/Sprachdaten können fast ohne Limitierung für die Forschung erhoben werden. Die darauf aufbauenden Datenmodelle erreichen eine immer höhere Komplexität. Daher bedarf es neuer Methoden, diese zu strukturieren und teilweise auch zu reduzieren (z. B. durch Algorithmen oder Visualisierungen), damit sie (er-)fassbar für den Anwender werden. Ein Problem bei der Umsetzung der korpushermeneutischen Theorie ist die bisher existierende Softwarelandschaft der Computer-/Korpuslinguistik. Viele Programme sind notwendig, um aus einem einfachen Rohtext ein visuelles Ergebnis zu erzeugen. Die Programme sind teilweise untereinander inkompatibel 1 - oder sie folgen ausschließlich einem der beiden Paradigmen 2. Im Vortrag wird ein von mir entwickeltes Programm vorgestellt, das diese Arbeit übernimmt und korpushermeneutische Analysen ermöglicht. Der CorpusExplorer ist kostenfrei verfügbar und übernimmt alle nötigen Arbeitsprozesse – angefangenen bei der Textaufbereitung, Trennung von Text und Metadaten, Annotation 3, bis hin zur Auswertung und Visualisierung (über 30 unterschiedliche Auswertungsmodule). Alles mit einem Tool, mit nur wenigen Mausklicks und vereint unter einer intuitiven Benutzeroberfläche. Der CorpusExplorer erlaubt sowohl corpus-driven als auch corpus-based Analysen und durch die zyklische Verschränkung der Werkzeuge die angestrebte korpushermeneutische Analyse. Im Vortrag wird auf konkrete Praxisbeispiele eingegangen und gezeigt, wie sich eine korpushermeneutische Analyse entwickelt. Ein exklusiver Vortragspunkt wird sein, dass neben dem Programm das CorpusExplorer-Framework erstmalig vorgestellt wird. Mit diesem werden zwei Dinge möglich. Zum einen kann der CorpusExplorer mit eigenen Funktionen erweitert werden (z. B. schreiben / anbinden neuer Tagger / Dateiformate, entwickeln eigener Analysemodule, uvm.). Zum anderen kann man den CorpusExplorer in eigene Programme integrieren. Ein Teil des Quellcodes (Import- / Export-Funktion), sowie Quellcode von An-Projekten wurde bereits veröffentlicht. Der Quellcode des Frameworks wird nach Abschluss des Promotionsprojekts freigegeben.
Hochschullehre: Eines der komplexesten Probleme, vor dem Dozenten und Institute stehen, die Korpuslinguistik in der Lehre praktizieren möchten und nicht oder nur bedingt auf Kompetenzen im Bereich Informatik bzw. Computerlinguistik zurückgreifen können, ist der immense Toolchain, der für einen erfolgreichen Seminarbetrieb erforderlich ist. Der CorpusExplorer bietet hier eine praktikable Lösung für alle, die schnelle Ergebnisse erzielen möchten. Selbst Studenten in den ersten Semestern können so in die Forschung hineinschnuppern und ihre eigenen Forschungsfragen selbstständig erkunden. Dabei stehen Forschung, empirisches Arbeiten und Auswertung/Ergebnisvisualisierung im Vordergrund, nicht aber das verwendete Programm. Der Vortrag wird Einblicke in den Seminaralltag mit dem CorpusExplorer sowie Anregungen geben, die mit den Hörern diskutiert werden können.
Bildanhang (Screenshots CorpusExplorer v2.0):
Annotationsansicht
Links: Korpora & Dokumente
Mitte: Annotiertes Dokument mit gewählter Hervorhebungen
Rechts: Gewählte Hervorhebungen (Annotationen)
Unten: Verfügbare Module des CorpusExplorers
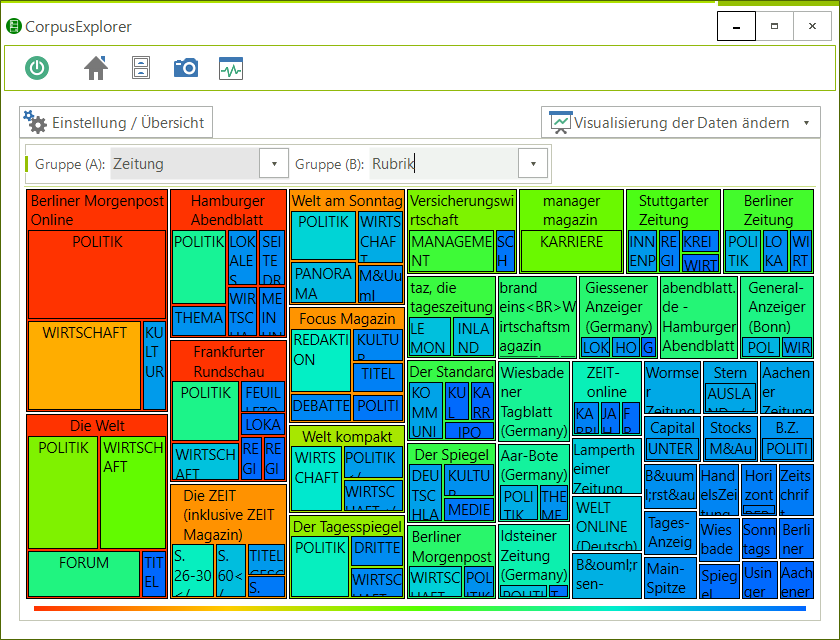
Korpusverteilung
Zu sehen ist ein Kreuzvergleich von Dokumentmetadaten. Eingenommene Fläche und Farbe (warm > kalt) sind bedeutungstragend
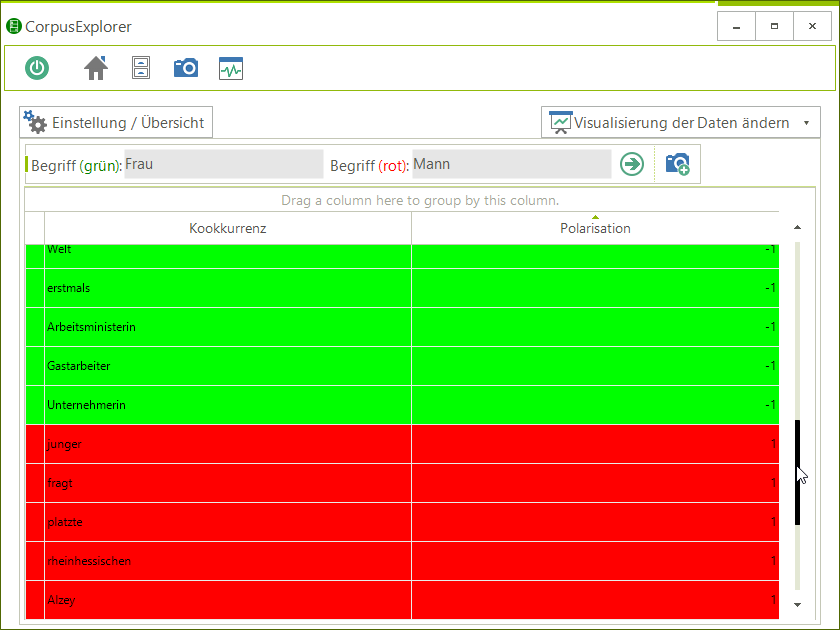
Begriffspaare / Oppositionswörter kontrastieren
Beispiel: Frau vs. Mann aus einem Zeitungskorpus (Frauenquote vs. Quotenfrau 2010-2014) via LexisNexis
Grün: Kollokatoren tendenziell Syrien
Schwarz: Gemeinsame Kollokatoren
Rot: Kollokatoren tendenziell Isreal
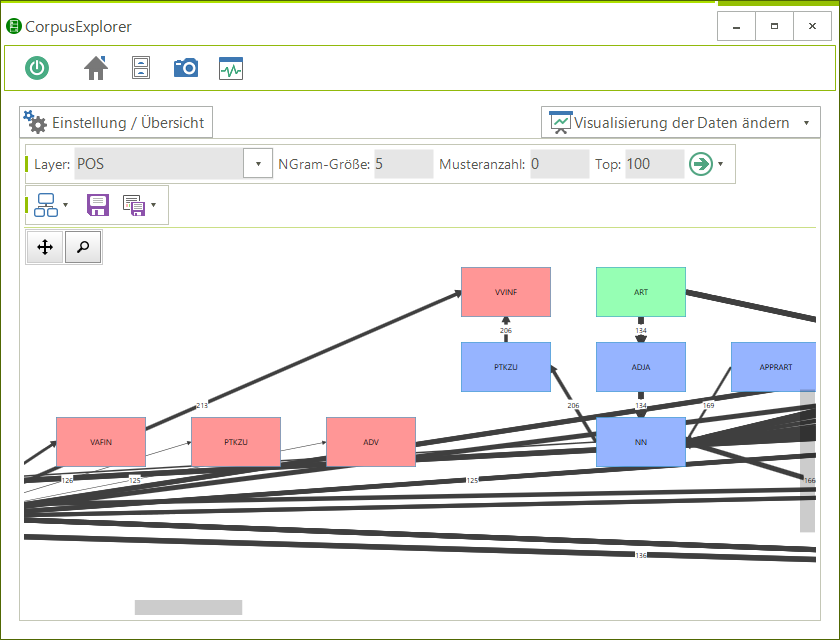
N-Gramm-Graph
Verknüpfung von N-Grammen auf Basis von POS-Tags
Graph: Grün: N-Gramm-Kopf, Blau: N-Gramm-Zwischenteil, Rot: N-Gramm-Ende
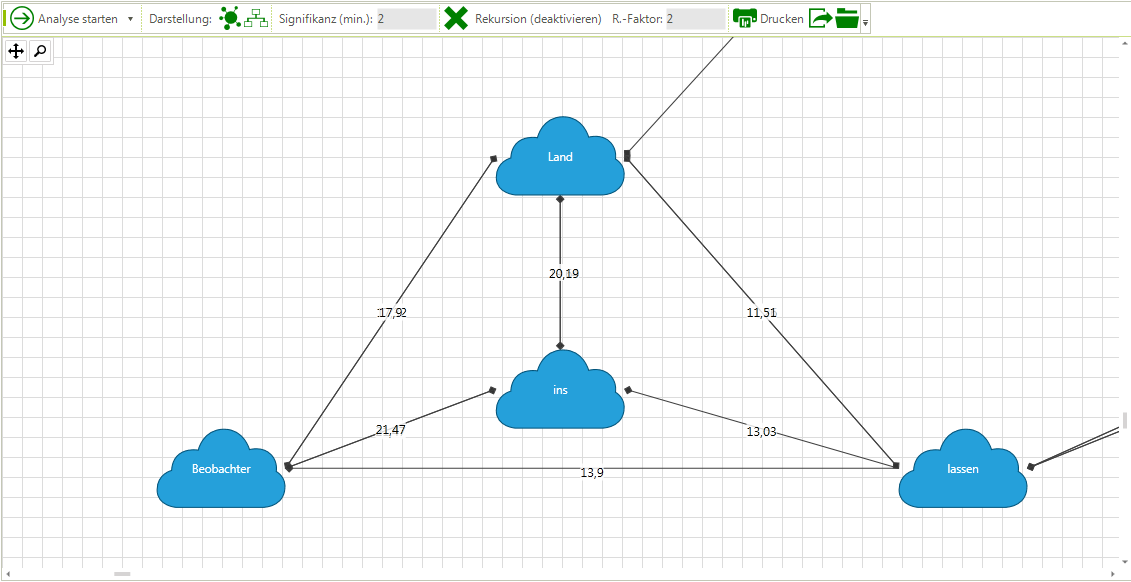
Kookkurrenzgraph
(Ausschnitt)
Das Beispiel zeigt einen per Rekursion ermittelten Teilausschnitt, der auf die Phrase: „Beobachter / ins / Land / lassen“ rekurriert.