1. Problemstellung und Vorarbeiten
Die Sanskrit-Grammatik Aṣṭādhyāyī („[Buch mit] acht Kapitel[n]“) des Linguisten Pāṇini, der wahrscheinlich gegen 350 v. u. Z. in Nordwest-Indien lebte, ist eine der ältesten wissenschaftlichen Grammatiken einer Sprache (Cardona 1976). Die Aṣṭādhyāyī bildet die Grundlage für eine bis heute kontinuierlich fortgeführte Tradition wissenschaftlicher Sanskrit-Linguistik in Indien, und ihr Einfluss auf die indische, aber auch auf die europäische Geistes- und Wissenschaftsgeschichte lässt sich kaum hoch genug ansetzen. Die Aṣṭādhyāyī systematisiert linguistische Phänomene des – seinerzeit wohl noch nicht verschriftlichten – spätvedischen Sanskrit und legt so die Grundlage für das klassische Sanskrit, die lingua franca von Wissenschaft, Philosophie und Literatur, die eines der größten vormodernen Textcorpora hervorgebracht hat. Daneben wirken Inhalt und Beschreibungsmethoden der Aṣṭādhyāyī auf beinahe jeden Bereich der altindischen Geistesgeschichte ein. Aus Sicht der westlichen Sprachwissenschaft entwickelt Pāṇini in der Aṣṭādhyāyī formale Methoden wie eine Metasprache oder Ersetzungsregeln, die heute zu den zentralen Elementen moderner linguistischer Theorien gehören (Kiparsky 2009).
Während der Inhalt der Aṣṭādhyāyī und die auf ihr gründende altindische Sanskrit-Linguistik in der Indologie intensiv erforscht wurden, wurde ihr Einfluss auf die Textproduktion und den Sprachwandel in Sanskrit weniger systematisch untersucht. Zum Sprachwandel ist anzumerken, dass das klassische Sanskrit nahezu ausschließlich für Literatur, Wissenschaft und Religion, aber nicht für die alltägliche Kommunikation eingesetzt wurde. Zudem hat die grammatikalische Tradition das Sanskrit als unveränderliche Sprache interpretiert (Deshpande 1993). Daher ist zu erwarten, dass der Sprachwandel im Sanskrit weniger stark ausgeprägt ist als bei gesprochenen Sprachen. Eine kursorische Lektüre von Sanskrit-Texten zeigt, dass das Pāṇinäische Regelsystem auf den Ebenen von Phonetik und Morphologie fast uneingeschränkt verwendet wurde. Die Aṣṭādhyāyī hat sich hier von einer ursprünglich deskriptiven zu einer präskriptiven Grammatik gewandelt und setzt einen „Goldstandard“, von dem sich Sprachvarianten wie z. B. das epische Sanskrit (Oberlies 2003) unterscheiden lassen.
Kaum erforscht ist bisher die Frage, inwieweit die Aṣṭādhyāyī nicht nur grammatische Phänomene wie z. B. Wortbildung oder Phonetik, sondern auch die Lexik des Sanskrit beeinflusst hat. Sind Wörter, die in der Aṣṭādhyāyī vorkommen, durch die über Jahrhunderte anhaltende Rezitation der Grammatik vor Sprachwandel geschützt? Hier schließt sich die Frage an, ob Autoren die Aṣṭādhyāyī selbst oder eine vereinfachende Darstellung als Referenzwerk verwendet haben. Aufgrund der Komplexität der Aṣṭādhyāyī formieren sich v.a. seit dem 11. Jahrhundert u. Z. neue grammatikalische Schulen, die auf der Aṣṭādhyāyī aufbauen, ihr Regelsystem aber vereinfachen und teilweise auch erweitern (Coward / Raja 1990: 19-20). Diese Schulen werden erst im 16. Jahrhundert durch Bhạṭtojī Dīkṣitas Grammatik Siddhāntakaumudī verdrängt, die die Pāṇinäische Tradition wiederherstellt, obwohl auch hier die Regeln neu angeordnet werden. Dazu passt Houbens Beobachtung, wonach sich die aktive Leserschaft der Aṣṭādhyāyī auf einen kleinen Zirkel von Spezialisten beschränkte (Houben 2008: 566), obwohl ihr die grammatikalische Tradition, wie Deshpande bemerkt, im Lauf der Jahrhunderte eine wachsende Wertschätzung entgegenbringt (Deshpande 1998).
Die vorliegende Studie schätzt den Einfluss des Vokabulars der Aṣṭādhyāyī auf die spätere Textproduktion mit einem corpusbasierten Ansatz ab. Dabei wird die zeitliche Verteilung Pāṇinäischer Beispielnomina (s. Abschnitt 2, 2, 2, and 2) in der Literatur des klassischen Sanskrit untersucht. Die Studie geht von Vorarbeiten in (Hellwig / Petersen 2015) aus, wo gezeigt wurde, dass das Beispielvokabular der Aṣṭādhyāyī im Lauf der Zeit immer seltener auftritt. Dieses Ergebnis widerspricht der These, dass die Verwendung von Worten in der Aṣṭādhyāyī diese vor dem Aussterben schützt. Allerdings ließ sich mit der in (Hellwig / Petersen 2015) verwendeten Datengrundlage nicht ermitteln, ob frühe Sanskrit-Nomina aus anderen Textklassen eine ähnliche diachrone Verteilung zeigen. Die vorliegende Studie erweitert den Referenzrahmen daher um eine zweite Gruppe von Nomina aus der frühen religiösen Literatur ( śruti, „das Anhören [‘heiliger’ Texte]“), deren Texte (Brāhmaṇas, Upaniṣads) in der Sanskrit-Tradition ebenso hoch geschätzt werden wie die Aṣṭādhyāyī. Die Verwendung von „religiösen Nomina“ wird mit derjenigen von Beispielnomina aus der Aṣṭādhyāyī kontrastiert.
2. Daten
Als Corpus dient das Digital Corpus of Sanskrit (DCS) mit rund 3.570.000 Tokens, dessen Texte automatisch tokenisiert und morphologisch-lexikalisch analysiert und danach manuell korrigiert wurden (Hellwig 2015). Alle Texte des DCS sind einer von fünf Hauptperioden der Sanskrit-Literatur zugeordnet. Die Struktur dieser Zeitachse stellt angesichts der Tatsache, dass zahlreiche wichtige Sanskrit-Texte anonym und ohne Datierung überliefert sind, gerade in den frühen Zeitschichten nur eine grobe Näherung dar (Hellwig 2010). Daneben sind alle Texte mit einem inhaltlichen Label versehen, das aus einem traditionellen Klassifikationsschema abgeleitet wurde.
Der Einfluss der Aṣṭādhyāyī auf die spätere Literatur wird anhand der Verteilung von 1341 Nominaltypen untersucht, an denen Pāṇini grammatikalische Phänomene exemplifiziert. Diese Beispielnomina werden in Pāṇini’s Metasprache von Nomina unterschieden, die auf ein externes Objekt referieren (sūtra 1.1.68 der Aṣṭādhyāyī, vgl. Séaghdha 2004: 19ff. für eine Übersicht über die Forschung). Während z. B. das Nomen nāsikā in sūtra 1.1.8 der Aṣṭādhyāyī auf die Nase referiert, 1 beziehen sich die Nomina deva und brahman in sūtra 1.2.38, das das vedische Akzente diskutiert, nicht auf einen Gott und einen Brahmanen, sondern werden in ihrer „lautlichen Erscheinung“ verwendet: “Bei [den Nomina] deva und brahman tritt der anudātta und svarita an die Stelle des svarita.” (Übersetzung nach Böhtlingk 1886; unsere Ergänzungen in eckigen Klammern). In der Datenbank Aṣṭādhyāyī 2.0, die den Text der Aṣṭādhyāyī mit zahlreichen grammatischen und semantischen Annotationen unterlegt, sind solche nicht-referierenden Beispielnomina explizit markiert (Petersen / Hellwig 2015). Dadurch lässt sich das Pāṇinäische Beispielvokabular problemlos für corpuslinguistische Studien erschließen.
Das Vergleichsvokabular der frühen religiösen Literatur entstammt wie die Aṣṭādhyāyī der frühesten Zeitschicht des DCS, die von der weiteren Auswertung ausgeschlossen wird. Da für die śruti keine äquivalenten wortsemantischen Annotationen vorliegen, werden aus dem śruti-Untercorpus die 1268 Nominaltypen ausgewählt, die mehr als einmal auftreten. Diese „ śruti-Nomina“ enthalten Begriffe wie loka („(Menschen- / Götter-)Welt“), ātman („Selbst“) und die Namen spätvedischer Gottheiten und spiegeln damit die zentralen Inhalte der śruti-Literatur wider.
Da das DCS weder thematisch noch zeitlich ausgewogen ist, beruhen die im folgenden dargestellten Verteilungen von Lexemen auf wiederholten Stichproben (samplings) fester Größe. Dazu wird das Corpus zuerst anhand von Zeitperioden und inhaltlichen Labels in Faktorstufen aufgeteilt. Anschließend werden aus jeder Faktorstufe 100 zufällige Stichproben von 500 Nomina gezogen. Für jede Stichprobe wird ausgezählt, wie viele der Referenzwörter vorkommen, und die resultierenden prozentualen Anteile werden für jede Faktorstufe gemittelt. Diese Mittelwerte bilden den Ausgangspunkt für die Auswertung im nächsten Abschnitt.
3. Auswertung
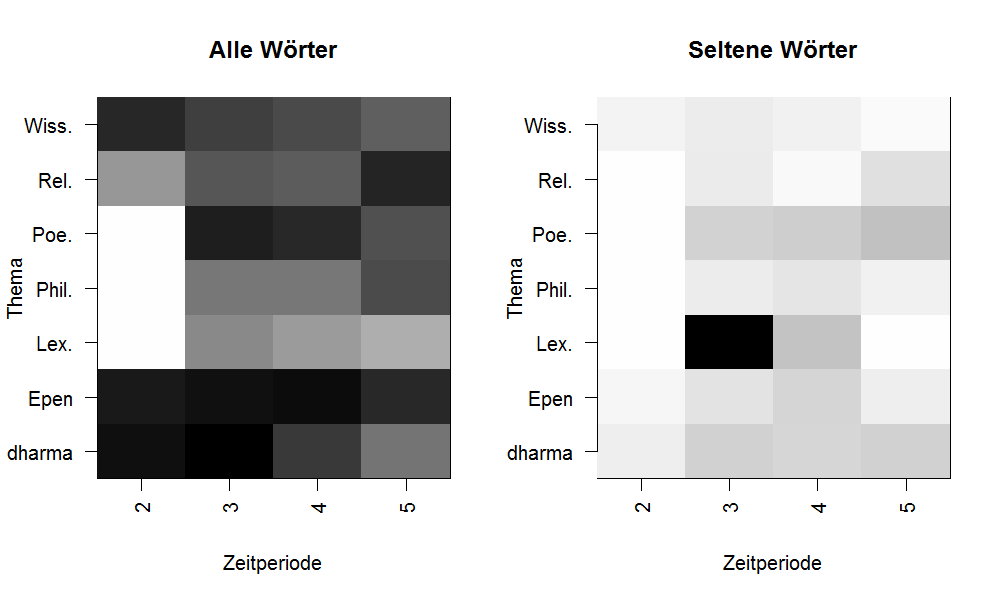
Abbildung 1 zeigt die gemittelten relativen Häufigkeiten, mit denen Beispielwörter aus der Aṣṭādhyāyī im späteren Sanskrit auftreten, alsheatmap, in der dunkle Farbtöne eine höhere durchschnittliche Häufigkeit in einer Faktorstufe anzeigen. Obwohl gerade seltene Beispielwörter in einigen Domänen wie der Sanskrit-Lexikographie (Zelle „Lex.“, Zeitstufe 3) gehäuft auftreten, nimmt die Verwendung des Pāṇinäischen Vokabulars insgesamt mit der Zeit ab. Dieses Ergebnis deutet darauf hin, dass der direkte Einfluss der Aṣṭādhyāyī auf das Sanskrit-Vokabular im Lauf der Zeit geringer wird.
Abb. 1: Verteilung von Beispielnomina aus der Aṣṭādhyāyī
Abbildung 1 klärt allerdings nicht, ob die Verwendungshäufigkeit bei Lexemen aus der Aṣṭādhyāyī weniger stark abnimmt als bei Lexemen aus anderen frühen Texten. In Abbildung 2 wird deshalb die zeitliche Verteilung Pāṇinäischer Beispielnomina derjenigen der śruti-Nomina in fünf Konfigurationen gegenübergestellt. Der linke Teilbereich zeigt, dass sich die Nomina aus beiden Gruppen grundsätzlich ähnlich über die Sanskrit-Literatur verteilen. Während in der epischen, wissenschaftlichen und „Rechtsliteratur“ eine allgemeine Abnahme früher Nomina zu beobachten ist, erleben sie in der religiösen und philosophischen Literatur eine Art revival. Die Analyse der daran beteiligten Begriffe zeigt, dass hierfür v.a. Begriffe wie yoga, prāṇa („Atem“), ātman („Selbst“) oder jñāna („Wissen“) verantwortlich sind, die z. B. in Yoga-Texten oder bei der damit verbundenen Mikro-Makrokosmos- Spekulation eine zentrale Rolle spielen.
Für die Plots auf der rechten Seite von Abbildung 2 wurde die Vereinigungsmenge des Pāṇinäischen Beispielvokabulars (P) und der śruti-Nomina (S) in die drei Teilmengen P∩ S (Schnittmenge), P∖ S (alle aus P, die nicht in S sind) und S∖ P (alle aus S, die nicht in P sind) aufgeteilt. Der allgemeine Trend dieser Detailverteilungen unterscheidet sich auf den ersten Blick nicht grundsätzlich von der linken Seite des Plots. Bemerkenswert ist allerdings der vergleichsweise hohe Anteil, den die Schnittmenge P∩ S am später verwendeten frühen Nominalvokabular einnimmt. Dieser Befund deutet aus unserer Sicht weniger auf eine verstärkte Rezeption Pāṇini’s hin als auf die Tatsache, dass die Aṣṭādhyāyī populäre Beispielwörter verwendet.
Abb. 2: Links: Verteilung von Nomina, die in der Aṣṭādhyāyī (dunkelgrau) und in der śruti (hellgrau) vorkommen. Rechts: Verteilung von Nomina, die in śruti und Aṣṭādhyāyī (dunkelgrau), nur in der Aṣṭādhyāyī (mittelgrau) und nur in der śruti (hellgrau) vorkommen.
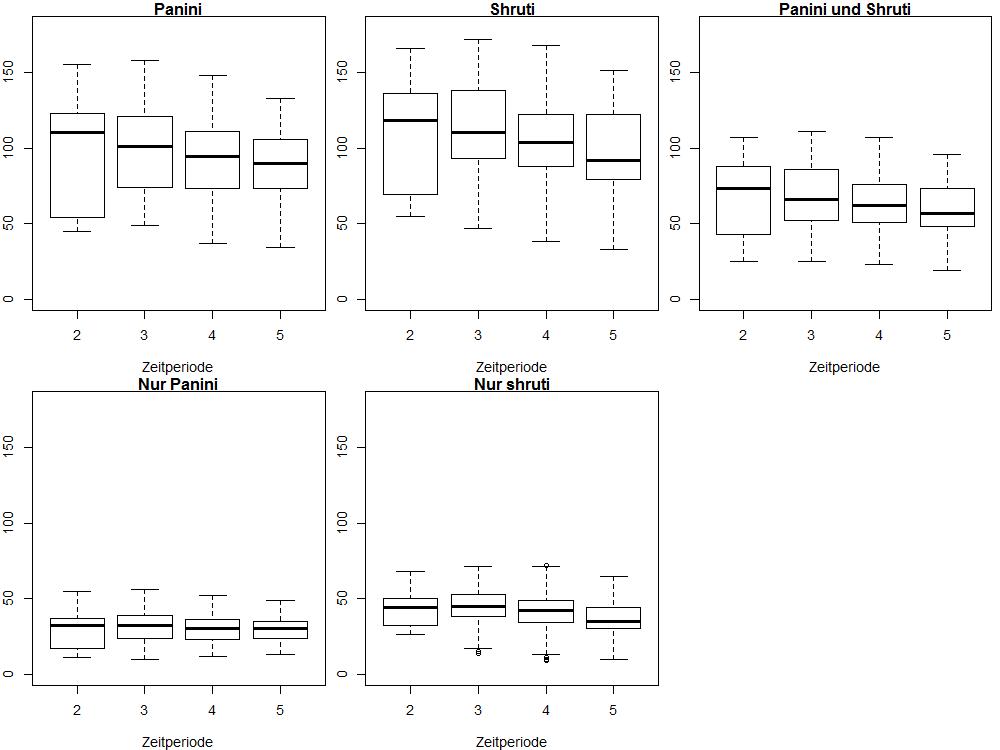
Abschließend werden die Häufigkeiten für alle fünf Konfigurationen pro Zeitperiode über alle Themengebiete gemittelt. Die drei oberen Plots in Abbildung 3 zeigen, dass der Kernbestand des spätvedischen Vokabulars im klassischen Sanskrit zunehmend seltener verwendet wird. Weniger eindeutig ist die Verteilung in den beiden unteren Plots, die eine geringe, aber recht konstante Verwendung der Nomina aus P∖ S erkennen lassen.
Diese geringere Abnahme des Pāṇinäischen Kernvokabulars scheint die These zu stützen, dass die Aṣṭādhyāyī dauerhaft rezipiert wurde und ihre Wörter durch diese regelmäßige Verwendung weniger stark dem allgemeinen Wandel der Lexik unterliegen. Allerdings muss diese Schlussfolgerung in zwei Punkten deutlich eingeschränkt werden. Erstens ist die Vergleichsgruppe der religiösen Texte nur deshalb bis heute überliefert, weil sie ebenfalls als wichtig angesehen und deshalb regelmäßig rezipiert wurden. Hier fehlt ein Corpus von Texten aus der Zeit Pāṇini’s, die danach keine Rolle mehr spielten. Zweitens sollten die Vergleichswörter aus der śruti genauer semantisch differenziert werden, da z. B. durch den hohen Anteil von Eigennamen für Gottheiten, die auch in späteren Texten eine wichtige Rolle spielten, die lexikalische Aussterberate in den śruti-Texten unterschätzt werden könnte. Dieser zweite Punkt wird in einer Folgestudie untersucht werden.
Abb. 3: Über Themengebiete gemittelte Häufigkeiten für die fünf Vergleichskonfigurationen