Die hier unter dem Arbeitstitel CFDB vorgestellte Datenbank stellt den derzeit einzigartigen Versuch dar, Fragen zur paläographischen Entwicklung der babylonischen Keilschrift im ersten vorchristlichen Jahrtausend mit den Mitteln der Digital Humanities zu beantworten. Sie wird im Zuge des unter der Leitung von Michael Jursa an der Universität Wien durchgeführten Projekts Diplomatik und Paläographie neu- und spätbabylonischer archivalischer Dokumente (FWF P 26104 ) am Austrian Centre for Digital Humanities der Österreichischen Akademie der Wissenschaften entwickelt. Diese Datenbank stellt ein dynamisches und flexibles Untersuchungsinstrument dar, das im Hinblick auf die neu- und spätbabylonische Epigraphik eine beträchtliche Lücke in der Forschung zu schließen beabsichtigt.
Verglichen mit alphabetischen Zeichensystemen weist die Keilschrift auf der Ebene des Schriftduktus eine hohe Zahl an potentiell objektivierbaren Merkmalen auf: Eigenschaften wie Schreibwinkel, Drucktiefe, Reihenfolge, Anordnung und Clustering von Keilen, Zeichengröße und andere Kriterien eignen sich ausgezeichnet für paläographische Untersuchungen. Vorrangiges Interesse dieser Seite des Forschungsprojekts ist die Identifizierung von gehäuft auftretenden standardisierten Zeichenformen (auf der Ebenen von Einzelzeichen und Ligaturen) bzw. die Frage, ob sich Abweichungen davon an die Größen Datum, Entstehungsort, Archiv oder Schreiber rückbinden lassen.
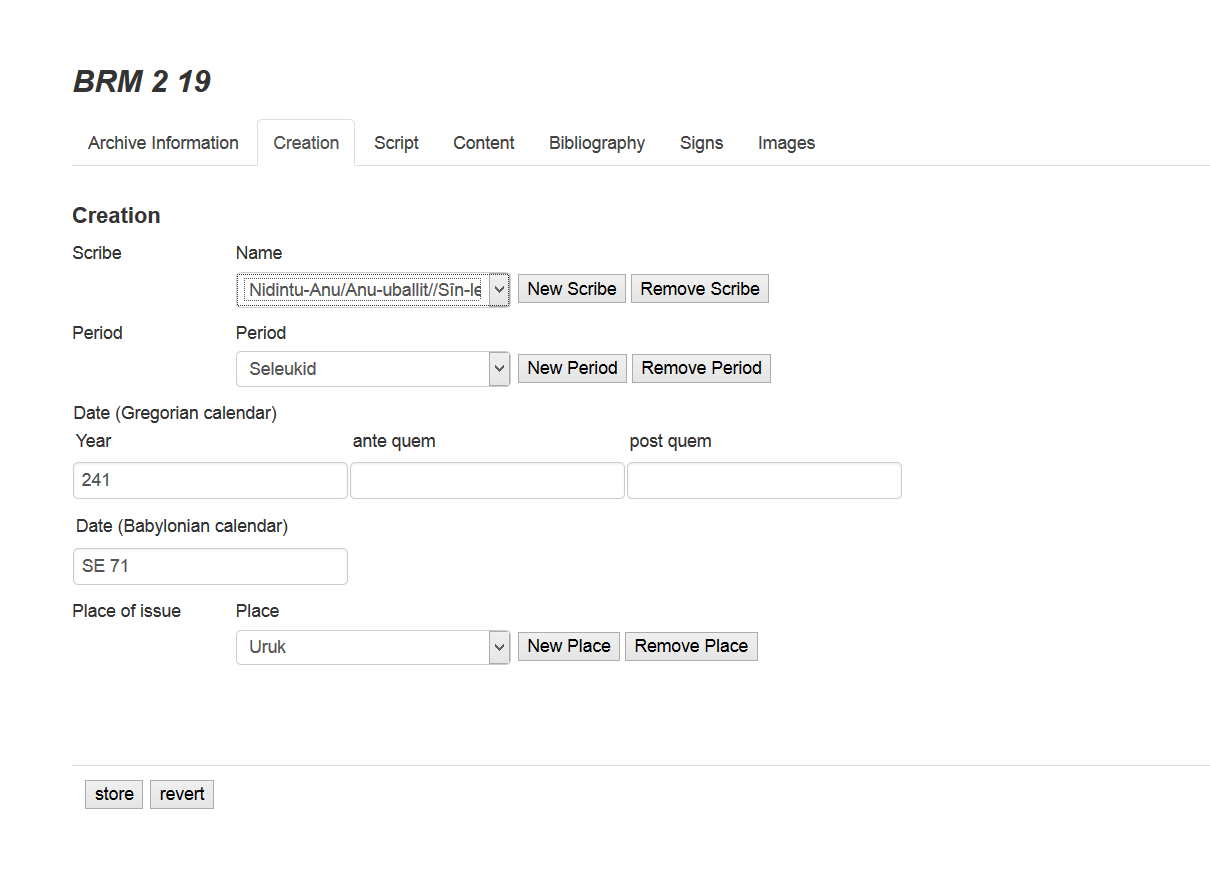
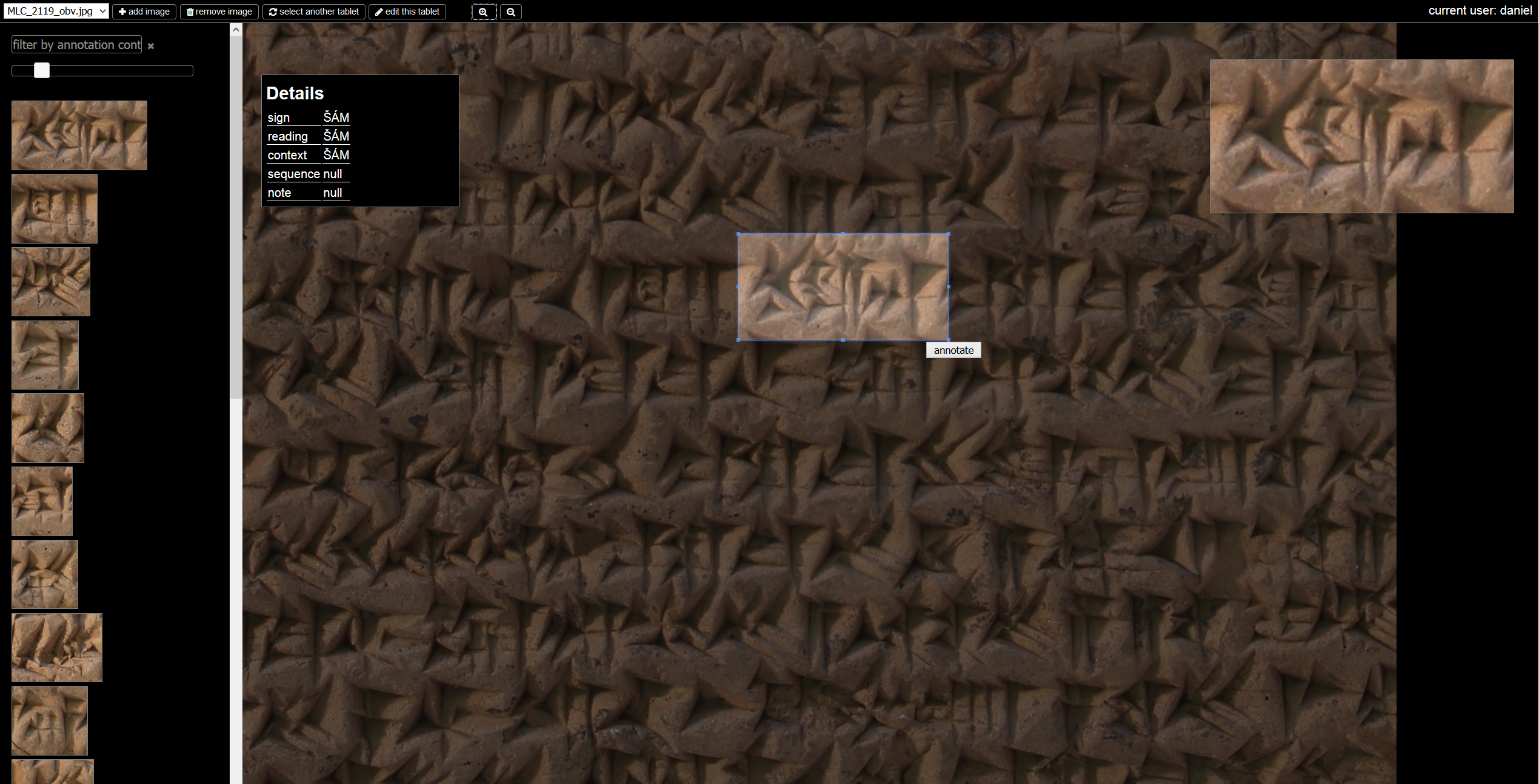
CFDB ist analog zu konventionellen assyrologischen Zeichenliste strukturiert: Jedem Graphem dieser Liste wird ein Korpus attestierter Formen (Allographen) in Form von annotierten Bildsegmenten beigestellt. Die Allographen werden anhand ihrer Datierung und Periodisierung sowie ihres Herkunftsortes, des Archives, der Textsorte und, sofern möglich, des Schreibers klassifiziert. Somit erlaubt CFDB die Untersuchung dieses Zeichenkorpus einerseits hinsichtlich des Verhältnisses verschiedener Allographen zueinander in einer diachronen Perspektive sowie andererseits in Bezug auf die oben genannten unterschiedlichen Aspekte des Schreibduktus, und zwar über die Ebene von Einzelzeichen oder -tafeln hinaus. Auf einer Metaebene bietet die Datenbank die Möglichkeit, in der Literatur häufig anzutreffende, allerdings lediglich impressionistisch begründete Differenzierungen zwischen „formalen“, „kalligraphischen“ oder „kursiven“ Schriftduktus zu objektivieren und zur Diskussion zu stellen.
Die Implementierung der Applikation, die sich derzeit im Beta-Stadium befindet und deren Quellcode im Laufe der Entwicklung der Forschungscommunity Open Source verfügbar gemacht werden wird, basiert auf der XML-Datenbank exist-db. Eine integrierte, browserbasierte Arbeitsumgebung erlaubt die Eingabe und Manipulation der Metadaten zu einzelnen Tafeln, die Bearbeitung der digitalen Standardzeichenliste, Upload und Verwaltung von einem oder mehreren Faksimiles einzelner Tafeln sowie die manuelle Bildsegmentierung nach Einzelzeichen und deren Annotation. Die Verwendung von XForms für die Dateneingabe einerseits und von REST-Endpoints für die Kommunikation zwischen Annotierungsoberfläche und Server anderseits ermöglichen es, Teile der Anwendung auch in verändertem technischen Kontext (bspw. vor einer relationalen Datenbank) wiederverwenden zu können. Die Applikation sieht sich damit auch als kleiner Beitrag zum Aufbau einer nachhaltigen, da modularen Forschungsinfrastruktur.
Das Datenmodell von CFDB beruht auf den aktuellen Guidelines der Text Encoding Initiative und verwendet Bestandteile der Module transcr (Kapitel 11: Representation of Primary Sources) für das Markup der Bild-Text-Relation sowie des gaiji-Moduls (Kapitel 5: Characters, Glyphs, and Writing Modes). Die digitale Version der Standardzeichenliste, die im Zuge des Projekts erstellten Bildsegmente, Transkriptionen sowie die zugehörigen Metadaten und Annotationen werden nach Projektende sowohl eingebettet in cfdb als auch als Datenset in TEI-XML der Forschungsöffentlichkeit zur Verfügung gestellt. Die Anbindung an relevante Initiativen zur Digitalisierung und zum Korpusaufbau von Keilschrifttexten (Cuneiform Digital Library Initiative CDLI, Neo-Babylonian Cuneiform Corpus NaBuCCo) ist geplant.
CFDB ist als ein dynamisches Werkzeug für Untersuchungen zur Keilschrift konzeptualisiert, das zur einfachen Referenz in Forschung und Lehre dient und mit Blick auf die Nachhaltigkeit von Forschungsdaten entwickelt wurde. Gleichzeitig kann die Applikation leicht für analog strukturierte Forschungsprojekte in anderen Bereichen der Bild-Text-Korrelation adaptiert werden.