1. Einführung
Das Abstract fokussiert die Frage, welchen Beitrag computergestützte Methoden für die Untersuchung multimodaler Daten in der angewandten Linguistik leisten können, welche Herausforderungen mit der Entwicklung verbunden sind und wie sich „traditionelle“ und computergestützte Verfahren wechselseitig bereichern. Einer der großen Vorteile computergestützten Arbeitens ist, dass der Forscher oder die Foscherin wesentlich größere Datenbestände analysieren kann und teilweise zu Aussagen kommt, die mit händischen Verfahren zeitlich wie personell kaum in Forschungsprojekten zu leisten sind.
Der Beitrag stützt sich auf Daten und Fragestellungen des DFG-geförderten Projektes ModiKo (2014-2017, GZ: JA1172/3-1). Ziel des Projektes ist die Entwicklung von Ansätzen und Methoden, die es erlauben, Formen und Funktionen von Modalitätsinterdependenzen (MID) in ihrer Musterhaftigkeit systematisch zu beschreiben und zu analysieren (Reimer et al. 2015; Ullrich et al. im Druck). Das Forschungsprogramm basiert auf gesprächsanalytischen Ansätzen, die gegenstandsbezogen erweitert werden durch korpus- und texttechnologische sowie computerlinguistische Ansätze. Teil des Projektes ist die Entwicklung eines Annotationstools für heterogene Datenbestände, mit dem Datenformate über mehrere Ebenen annotiert, Annotationen datenformatübergreifend in Bezug gesetzt und in ihrem Bezug dargestellt werden können.
Bisher fehlen für die systematische Beschreibung und Analyse von MID-Formen und Funktionen geeignete Ansätze, Methoden und Tools (Jakobs et al. 2011). Der vorliegende Beitrag gibt einen Einblick in die laufende Projektarbeit. Er diskutiert methodische Herausforderungen anhand der Frage, wie sich mit computergestützten Methoden verbale Thematisierungen von MID (MID-anzeigende Lexeme und Mehrwortlexeme) über große Datenbestände hinweg ermitteln lassen. Verbale Thematisierungen liefern Hinweise auf das Auftreten von Modalitätsinterdependenzen. Zwar können keine exakten Angaben über das Auftreten von MID gemacht, händische Analysen so jedoch vereinfacht werden.
Im Folgenden werden der Stand der Forschung, das im Projekt untersuchte Fallbeispiel und das Korpus beschrieben. Im Anschluss wird beispielhaft gezeigt, wie die Auseinandersetzung mit den Forschungsgegenständen (hier: verbale Thematisierung von MID) die Entwicklung von Methoden vorantreibt. Es werden Ergebnisse der Arbeiten in ModiKo aufgezeigt und ein Fazit gezogen.
2. Stand der Forschung
Modalitätsinterdependenzen (MID) sind definiert als Zusammenspiel komplexer Ausdrucksressourcen wie Sprechen, Schreiben und graphisch-symbolisches Visualisieren (Fiehler 1980), wie sie in professionellen Interaktionssituationen von den Interaktionsteilnehmer_innen zu bestimmten Zwecken genutzt und situationsabhängig kombiniert werden (Ullrich et al. im Druck). Das Eintreten einer Modalitätsänderung wird von den Interaktionsbeteiligten häufig verbal thematisiert, etwa durch MID-anzeigende Einzellexeme (z. B. schreiben) oder Mehrwortlexeme (z. B. ich schreib das mal hier rein). Die Thematisierung bezeichnen wir als Modality-taking.
3. Fallbeispiel
Die untersuchten MID sind Teil eines Fallbeispiels, das in einem Vorgängerprojekt (IMIP: Interdisziplinäre Methoden industrieller Prozessmodellierung, BMBF, 2008-2011; Jakobs et al. 2011) in der sachgüterproduzierenden Industrie erhoben wurde. Im Fallbeispiel werden Prozesse im Unternehmen von Prozessmodellierern im Gespräch mit Mitarbeitern erhoben und modelliert (Eraßme et al. 2015). Interaktionsbegleitend machen sich die Beteiligten (Prozessmodellierer und Unternehmensmitarbeiter) Notizen oder fertigen Skizzen an. Sie nutzen diese als intermediäre Objekte (Jeantet 1998) für die interaktive Rekonstruktion der Gesprächsinhalte.
4. Korpus
Die in ModiKo genutzten Daten stützen sich – wie oben erwähnt – auf das Vorprojekt IMIP. Der aus IMIP übernommene (Teil-)Datensatz umfasst 548 Minuten Videoaufzeichnung und 89 gescannte Dokumente sowie 266 Transkriptseiten.
Die Analyse der Daten erforderte eine Reihe methodischer Anpassungen, die im Folgenden beschrieben werden.
5. Methodenentwicklung
Für das übergeordnete Ziel der musterhaften Beschreibung von MID konzentrieren sich die Analysen in ModiKo auf die Textdokumente des IMIP-Datensatzes (Transkripte). Es stellte sich heraus, dass zahlreiche Anpassungen und Überarbeitungen der aus dem Vorgänger-Projekt stammenden Datensätze erforderlich waren. So zeigte sich zum Beispiel, dass die ursprünglich nach GAT 2 (Selting et al. 2009) erstellten Transkripte zu statisch waren für eine adäquate Erfassung und Notation interaktionsbegleitender Phänomene (z. B. die Erfassung genutzter Objekte, Kontextinformationen). Um das Problem der mehr oder weniger statischen Beschreibung verbaler Interaktionen in Textdokumenten (Transkript) zu lösen, werden die Transkripte in das Tool EXMARaLDA (Schmidt / Wörner 2014) eingelesen. EXMARaLDA ermöglicht eine Mehrebenen-Annotation. Eine geeignete Annotation von MID in den Interaktionsausschnitten erfordert jedoch eine Erweiterung von EXMARaLDA. Die Erweiterung zielt auf eine größtmögliche Flexibilität in der Annotation von MID-bezogenen Phänomenen als Voraussetzung für die Identifizierung von Mustern (z. B. für MID-anzeigende verbale Thematisierungen).
Eine weitere methodische Neuerung ergibt sich mit der Unterscheidung von drei Typen von Dokumenten: Primär-, Sekundär- und Tertiärdokumente.
Primärdokumente sind Videodateien der erhobenen professionellen Interaktionen sowie Scans der Skizzen, die von den beteiligten Akteuren in der Interaktion angefertigt werden (Berg / Milmeister 2008).
Sekundärdokumente sind multimodale Transkripte (auch: Verbaltranskripte) der Primärdokumente (s. auch Schmitt / Dausendschön-Gay 2015). Multimodale Transkripte erfassen die Komplexität verschiedener Ausdrucksressourcen, die die Interaktionsbeteiligten in der Interaktion nutzen (wie praktische Handlung, Verbales, Mimik, Blickrichtung, Gestik oder die Position im Raum).
Die Kategorie Tertiärdokument wurde in ModiKo geprägt, um einen dritten Typ von Dokumenten terminologisch fassen zu können – die Mehrebenen-Annotation von Sekundärdokumenten (Reimer et al. 2015). Tertiärdokumente geben dem Forscher die Möglichkeit, Sekundärdokumente durch die Notation verschiedener Phänomene wie sprachbegleitende Gesten (z. B. auf etw. zeigen), (materielle) Objekte (z. B. Klemmbrett, Kugelschreiber) sowie kontextuelle und verbale Informationen zu ergänzen. Das für MID-bezogene Phänomene zu entwickelnde Annotationssystem orientiert sich an dem in Trevisan (2014) entwickelten Mehrebenen-Annotationsansatz und adaptiert ihn gegenstandsspezifisch.
Im Laufe des Projektes sollen die Erweiterungen von EXMARaLDA erlauben, alle drei oben genannten Typen von Dokumenten in ein und dem selben Tool zu erfassen und bezogen aufeinander zu analysieren (bisher fehlt die Integration der Videos und der Scans als Teil der Primärdokumente).
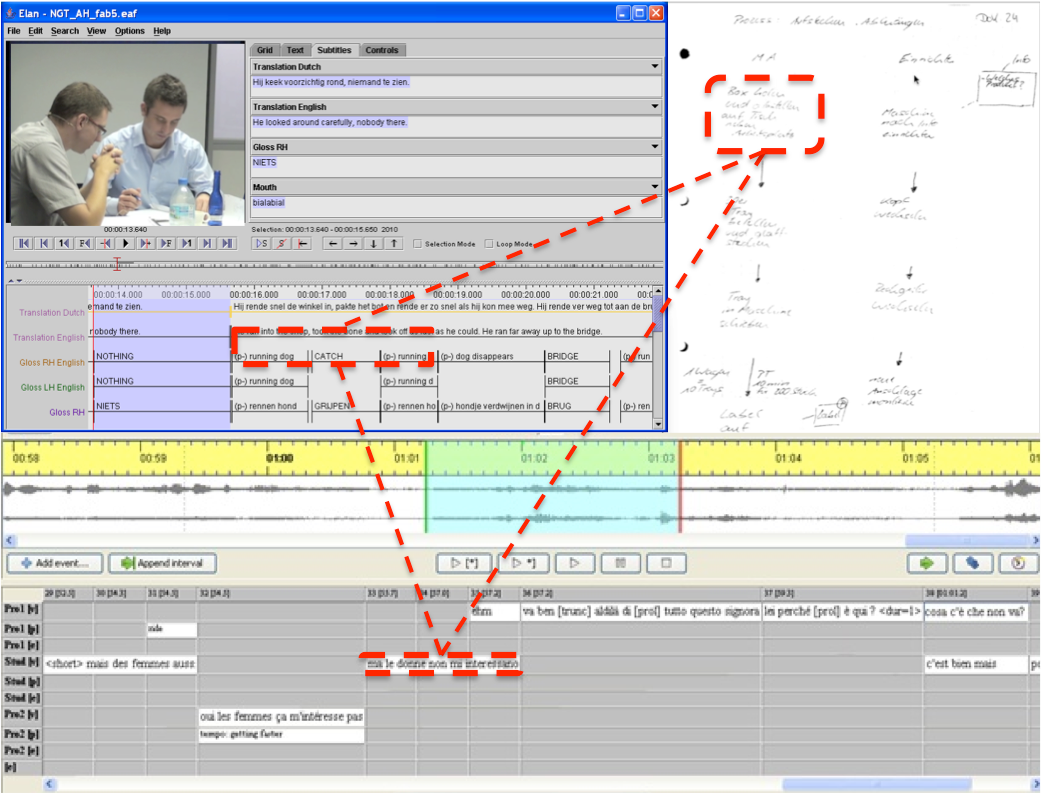
Zu den Langzeitzielen der Toolentwicklung gehört, dass das Tool Forscher digital dabei unterstützt, MID-bezogene Muster zu identifizieren und abzubilden. Die Identifizierung und Abbildung dieser Muster soll durch das in Beziehung setzen von Einträgen verschiedener Dokumenttypen ermöglicht werden (vgl. Abbildung 1).
Zukünftige Arbeiten betreffen die Visualisierung und Umsetzung des Zusammenspiels der unterschiedlichen Datenformate und Modalitäten (Videos, Scans der Skizzen, Transkripte, Mehrebenen-Annotation). Die Toolentwicklung soll es ermöglichen, dem Forscher verschiedene Datenformate in einem visuellen Bezugsfeld (Screen) anzuzeigen und sie dort in Bezug zu setzen (in Abbildung 1 beispielhaft rot markiert).
6. Ergebnisse
Für die Ermittlung verbaler Thematisierungen von MID wurde im Projekt ModiKo ein Analyseverfahren entwickelt, das händische und computergestützte Methoden kombiniert. Im ersten Schritt (händische Analyse) wurden alle Sekundärdokumente in ihrer Erhebungslogik händisch auf MID-anzeigende Lexeme durchsucht. Die identifizierten MID-anzeigenden Lexeme wurden extrahiert und systematisch als Lexikon aufbereitet. Im zweiten Schritt (computergestützte Analyse) wurde die Auftretenshäufigkeit verbaler Thematisierungen mit dem Tool AntConc 1 ermittelt. Zu diesem Zweck wurden die Transkripte in ein AntConc-kompatibles Format (.txt) überführt, in AntConc eingelesen und quantitativ analysiert.
Die händische Auswertung ergab, dass primär Verben (hier: malen, schreiben) aber auch Substantive (z. B. Blatt, Bleistift) und Adverbien (z. B. hier, da) Modalitätsänderungen anzeigen. Dies bestätigte sich in der quantitativen Analyse: Eine außerordentliche hohe Anzahl an Fundstellen konnte für die Verben schreiben (n = 157) und machen (n = 531) sowie für die Adverbien hier (n = 840) und mal (n = 149) identifiziert werden.
Besonders hervorzuheben ist die Verwendung von verbalen Thematisierungen von MID in Form von Mehrwortlexemen (z. B. ich setz das mal hier vor). Bezogen auf das Gesamtmaterial lassen sich für interaktionsspezifische Aufgaben Trigramme (z. B. ich mach mal) bestimmen, die das Eintreten einer Schreibhandlung oder etwa das Skizzieren von Prozessen andeuten.
7. Fazit
Die Verbindung qualitativ-händischer Verfahren mit quantitativ-computergestützten Verfahren bietet neuartige, sehr vielversprechende Forschungsergebnisse, die mit händischen Verfahren allein so im normalen Forscheralltag nicht zu erreichen wären. Im vorliegenden Beitrag wurde aufgezeigt, wie im Projekt ModiKo computergestützte Verfahren genutzt werden, um verbale Thematisierungen von MID im Korpus identifizieren und analysieren zu können. Durch die Einschränkung der zu untersuchenden Datenmenge mittels computergestützter Verfahren wird die notwendige händische Analyse vereinfacht. Zukünftig soll das Verfahren durch zusätzliche Analysen verfeinert werden, um eine exaktere Bestimmung / Identifikation von MID zu erreichen, etwa durch die Einschränkung des zu analysierenden Textfensters oder die Bestimmung zusätzlicher MID-anzeigender Indikatoren.
Die Integration von computergestützten Verfahren in linguistische Analysen erfordert andererseits ein erhebliches computerlinguistisches Know-how für die Adaption und Weiterentwicklung existierender Tools, das bislang kaum Teil der Ausbildung von Linguisten ist und die Zusammenarbeit mit Spezialisten erfordert. Auf längere Sicht erfordert die digitale methodisch-theoretische Weiterentwicklung von Disziplinen wie der Linguistik auch ein Umdenken in den universitären Ausbildungsprogrammen.