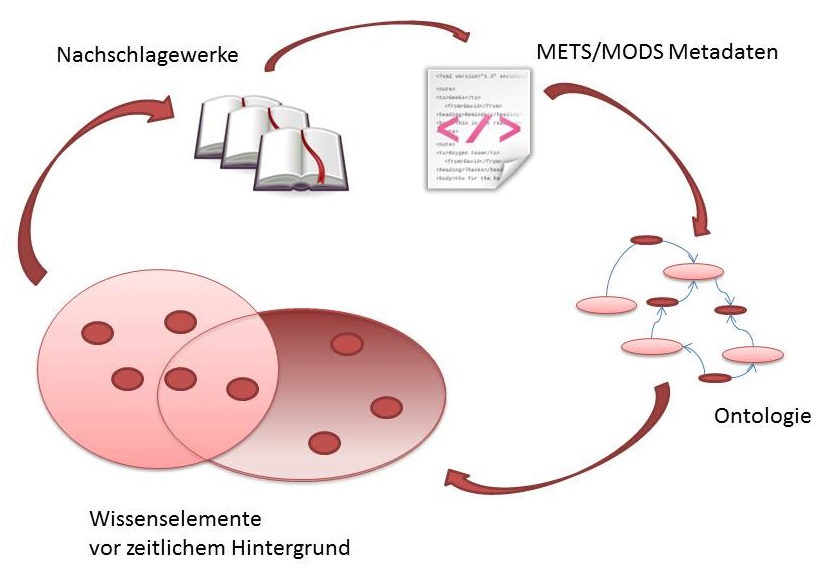
Historische Begriffe der entstehenden Erziehungswissenschaft sollen als maschinenlesbare Terminologie für digitale historische Bildungsforschung bereitgestellt werden. Bibliografische Titelaufnahmen von Lemmata aus 24 historischen erziehungswissenschaftlichen Nachschlagewerken (1774 – 1942) werden hierfür in eine Ontologie transformiert (Abbildung 1). Die Lexikonbeiträge dokumentieren Herausbildung und Wandel erziehungswissenschaftlicher Fachsprache und Gegenstände. Christian Ritzi (2003: 114) zeigte anhand der „Prügelstrafe“, wie diese "in pädagogischen Nachschlagewerken als pädagogisches Problem im Sinne einer 'Kodifizierung des Wissens' in das System des ausgebreiteten pädagogischen Wissens integriert" wurde. Das Beispiel illustriert das Potential, das für die Forschung in einem integrierten, semantisch modellierten, historischen Vokabular liegt. Im Fachportal Scripta Paedagogica Online (SPO) (vgl. BBF) sind die digitalisierten und detailliert mit Metadaten beschriebenen Lexika (Ritzi 2003: 103ff.) bereits frei zugänglich.
Abb. 1: Rekonstruktion einer Wissensdomäne aus bibliografischen Daten
Ell et al. (2013) haben gezeigt, wie Bibliografische Daten zur Bildungsgeschichte in die virtuelle Forschungsumgebung Semantic CorA (vgl. German Institute for International Educational Research et al.) zur semantischen Repräsentation und Analyse integriert werden können. Die digitalen Dienste der Bibliothek für Bildungshistorische Forschung (BBF) können künftig über die Bereitstellung von Daten hinausgehen und gegenüber den bestehenden Funktionen um eine Wissens-Ebene erweitert werden (vgl. Oramas et al. 2014; Feng et al. 2005), um die Bildungsgeschichte bei ihrer Hinwendung zu digitalen Methoden optimal zu unterstützen.
Im hier dargestellten Ansatz werden bibliografische Titeldaten als Begriffe bzw. Entitäten konzeptualisiert, neu modelliert und semantisch angereichert. So können sie in bildungshistorischen Analysen ausgewertet oder als Datensets für Textanalysen verwendet werden. Diese zu Forschungsdaten transformierten Katalogdaten erweitern somit die Informationsinfrastruktur für die historische Bildungsforschung auf der Wissens-Ebene und stellen exemplarisch einen neuen bibliothekarischen Infrastrukturservice für Digital Humanities dar, der in der Erzeugung und Bereitstellung semantischer Vokabulare besteht.
Als Ausgangsmaterial liegen in SPO frei zugängliche METS / MODS-Metadatensätze digitalisierter Nachschlagewerke und Lemmata im RDF / XML-Format vor. Mittels XSLT können sie auf die für das Vorhaben relevanten Elemente reduziert und umgeformt werden. Die als Wissenselemente betrachteten Titeldaten werden dabei aus der Wissensdomäne Buch- und Bibliothekswesen in die Wissensdomäne historische Bildungsforschung überführt. Die Ontologie wird als Linked Open Data (LOD) in RDF aufgebaut.
Jedes Lemma wird im ersten Verarbeitungsschritt zum Deskriptor eines Konzepts, das durch den zugehörigen Lexikonbeitrag definiert wird. Das Vokabular wird in SKOS (vgl. W3C 2012) modelliert, indem die Instanzen umklassifiziert werden. In den Metadaten befindliche Identifier für Katalogeinträge und digitale Dokumente werden mitgenommen und erhalten die Beziehung zu den Quellen. Im folgenden Schritt werden die erzeugten Vokabulare so überarbeitet, dass explizite Begriffsbeziehungen innerhalb jedes einzelnen Nachschlagewerks abgebildet werden. Zunächst wird jedes Nachschlagewerk einzeln transformiert. Anschließend werden die so entstandenen historischen Vokabulare zur Pädagogik durch Terminologiemapping (vgl. Keil 2012) aufeinander bezogen.
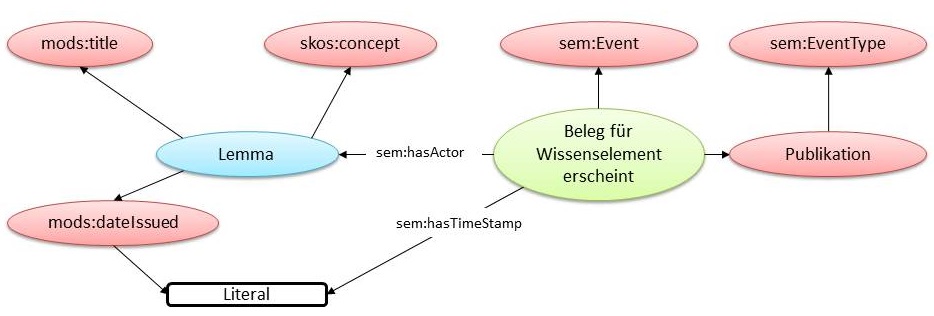
Abb. 2: Schematische Darstellung des Transformationsmodells
Eine besondere Herausforderung stellen Erhalt und Darstellung des zeitlichen Wandels von Sprachgebrauch und Kategorien dar. Für die Abbildung des Zeitbezugs wird jedes Nachschlagewerk als Snapshot-Ontologie modelliert (vgl. Ide / Woolner 2007: 142; Kauppinen / Hyvönen 2007). Jeder Begriff wird mit dem Erscheinungsdatum des ihn beinhaltenden Nachschlagewerks assoziiert, welches als „Publikationsereignis“ im Simple Event Model (SEM) (van Hage et al. 2011) modelliert wird (Abbildung 2). Da die aus den Lexika extrahierten Lemmata viele Überschneidungen aufweisen werden, sollen sie abschließend auch in einer einzigen Ontologie zusammengeführt werden (vgl. Kalfoglou / Schorlemmer 2003: 4).
Im Ergebnis entsteht eine Ontologie zu historischen Begriffen der Erziehungswissenschaft, die zur Nachnutzung in einem geeigneten Forschungsdatenrepositorium publiziert wird. Damit die Zuverlässigkeit der Daten gewährleistet und überprüft werden kann, werden auch Datensätze der Teilergebnisse zusammen mit den Metadaten des Transformationsprozesses dokumentiert. Damit bleibt jeder Verarbeitungsschritt replizierbar (Abbildung 3). Aus der neuen Datenbasis lassen sich Versionen ableiten, die bspw. als Gazetteer für automatische Entitätenerkennung, Entity Linking, Netzwerkanalysen oder visuelle Datenexploration eingesetzt werden können.
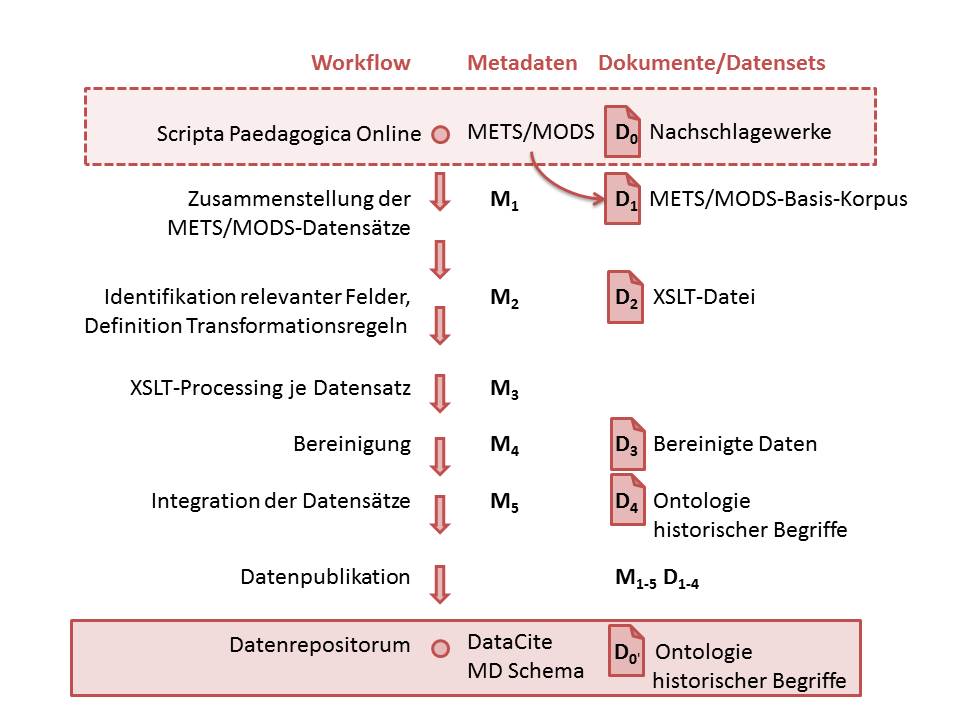
Abb. 3: Workflow zur Transformation und Erzeugung von Daten- und Metadatensets