Dieser Beitrag soll das Konzept des neu eingerichteten Stuttgarter DH-Zentrums CRETA 1 vorstellen, das mit literatur-, sprach-, geschichts- und politikwissenschaftlichen sowie philosophischen Fragestellungen sehr unterschiedliche textorientierte Fachdisziplinen vereint und das auf der anderen Seite Methoden und Modellierungstechniken aus dem maschinellen Lernen, der Computerlinguistik und aus der computergraphischen Visualisierung nicht nur zur Anwendung bringt, sondern begonnen hat, diese in eine gemeinsame DH-Methodik der tiefen reflektierten Textanalyse zu integrieren. Eine solche Weiterentwicklung des Methodeninventars der Digital Humanities ist ein langer Weg und braucht viele Beteiligte. Aspekte der Konzeption können wir jedoch bereits anhand von Fallstudien zu Szenarien aus laufenden Digital Humanities-Projekten konkret illustrieren, und es erscheint uns wichtig, den Ansatz breit zur Diskussion zu stellen.
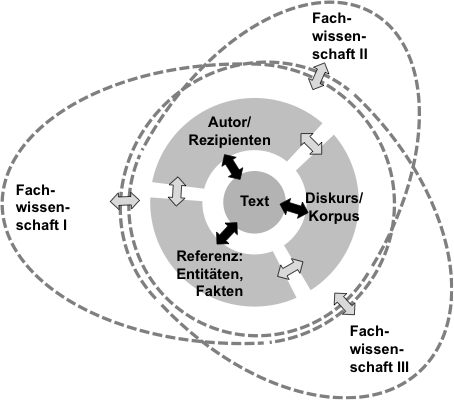
Das methodische Konzept hinter CRETA geht einerseits aus von der strukturellen Gleichartigkeit vieler Teilfragestellungen über ganz unterschiedliche Teilgebiete der Digital Humanities hinweg (eingebettet in sehr unterschiedliche Gesamtzusammenhänge und methodische Rahmenbedingungen). Beispielsweise findet sich das Teilziel einer systematischen Kategorisierung von Relationen, die in einer Textquelle zwischen zwei realen oder fiktionalen Personen ausgedrückt ist, in geschichtswissenschaftlichen Fragestellungen ebenso wie in sprach-, literatur- oder sozialwissenschaftlichen Gesamtuntersuchungen. Abbildung 1 skizziert weitere Typen von wiederkehrenden Fragestellungen, die disziplinübergreifend bei der Auseinandersetzung mit Texten (und allgemeiner mit kulturellen Werken) auftauchen und bei deren Modellierung daher Synergien zu erwarten sind. Eine komputationelle Modellierung des Teilfrage-Typs kann so für ganz unterschiedliche Rahmenuntersuchung die Erschließung größerer Korpora per Aggregation über Aspekte des Textinhalts bzw. der –form erschließen.
Abb. 1
Zugleich anerkennt das methodische Konzept die Unterschiedlichkeit sowohl der jeweiligen inneren Ausprägung der Fragestellung (so gehen im genannten Beispiel Texteigenschaften und Relationstypen weit auseinander) als auch der interpretatorischen Anforderungen, die sich aus dem jeweiligen Modellierungs- und Fragekontext ergeben. Das technische Ziel, eine einzige optimale Werkzeuglösung für jede der fachübergreifend identifizierten Teilfragen zu entwickeln bzw. aus dem Text Mining oder Data Mining zu übernehmen, greift also zu kurz. Für die Mehrzahl der Einsatzgebiete wäre die Lösung suboptimal, und bei der Anwendung wäre schwer zu unterscheiden, in welchen Aspekten sie den methodischen Ansprüchen der einbettenden Untersuchungen genüge tut und in welchen nicht. Also sollten die gleichartigen Teilfragen zwar gemeinsam gedacht werden, als Instanzen derselben Modellklasse. Sie können (und müssen teilweise) jedoch für den jeweiligen Kontext angepasst und optimiert werden.
Der zentrale CRETA-Gedanke zur Erschließung von disziplinübergreifenden Synergien ist folgender: Für eine praktisch umsetzbare und dennoch methodisch adäquate Integration in die jeweilige Gesamtfragestellung kann es vorteilhaft sein, Modellinstanzen anfänglich auch über Kontexte hinweg zu übertragen, deren Randbedingungen nicht in vollem Maße übereinstimmen, die eingebetteten Teilmodelle aber sehr bewusst als vorläufig anzusehen – als Gegenstand eines fortlaufenden Verbesserungsprozesses (ganz im Sinne des Modellierungsbegriffs, den McCarty (2005) als Kernelement der Digital Humanities identifiziert). Die ohnehin angezeigte methodenkritische Hinterfragung des eingeschlagenen Weges (die jedoch gerade beim Einsatz von komputationellen Werkzeugen häufig nicht oder nicht in ausreichender Tiefe erfolgt) rückt damit zentral ins Blickfeld, und es ist nicht nur eine Frage des Nutzungskomforts, dass ein Instrumentarium zur Verfügung gestellt werden, das eine reflektierte Diagnostik der ineinandergreifenden komputationellen und klassischen Analyseschritte ermöglicht.
Folgerichtig wird bei aufgedeckten Unzulänglichkeiten die Anpassung der Modellierungslösung für eine Teilfrage an die kontextuellen Anforderungen zu einer Aufgabe, die nicht in der technisch-digitalen Peripherie einer geisteswissenschaftlichen Studie zu bearbeiten ist, sondern ihr kommt durch das Gesamtgeflecht aus Teilschritten für die übergeordnete Untersuchungsfrage zentrale Bedeutung zu.
Die notwendigen Anpassungen der vorläufigen Modellinstanzen lassen sich mit Techniken aus der Informatik (insbes. maschinellen Lernverfahren) prinzipiell ohne weiteres umsetzen – dabei muss jedoch die Zielrichtung der Optimierung vorgegeben sein (beim maschinellen Lernen in der Regel unterschiedliche Eingabe- / Ausgabe-„Trainingsdatensätze“, anhand derer die Parameter für eine gegebene Modellklasse eingestellt werden). Und hier beginnt die eigentliche Herausforderung für eine echte fachübergreifende Methodenintegration: selbst wenn man – rein hypothetisch – für eine geisteswissenschaftliche Gesamtfragestellung eine ausreichende Menge von Eingabe- / Ausgabe-„Daten“ bereitstellen könnte (also eine Annotation der interpretatorischen Zielkategorien für repräsentative Texte / Textabschnitte), die eine Modell-Optimierung ermöglichen würde, müsste dieser (vermutlich extrem ressourcenintensive) Prozess für jede Studie neu vorgenommen werden, da die gleiche Gesamtfragestellung in den Geisteswissenschaften wohl niemals zweimal gestellt wird. Methodische Erkenntnisse zu empirischen Faktoren bei der Modellierung aus einer Studie ließen sich nur schwer auf eine andere übertragen. (Abgesehen davon dürfte mit der Bereitstellung einer vollständig adäquaten Zielannotation häufig auch die Gesamtfragestellung gelöst sein, so dass der Bedarf an einer komputationellen Modellierung hinfällig wird.)
Naheliegender Weise wird man vielmehr versuchen, Modelle für relativ eng umrissene Teilfragestellungen empirisch zu optimieren, die dann in ein Geflecht von Analyseschritten einfließen. Der Annotationsaufwand für die Erzeugung von Referenzdaten hält sich damit in vertretbaren Grenzen und Erkenntnisse zu studienübergreifend gleichartigen Teilaspekten lassen sich so systematisch übertragen.
Der Identifikation von sinnvollen Teilfragestellungen, die über unterschiedliche Projekt- und Fachkontexte hinweg tragen – einer „Modularisierung“ – kommt also auch aus praktischen Erwägungen heraus eine zentrale Bedeutung zu. Was aus informatischer Sicht wie eine Binsenweisheit klingt, ist jedoch in der Modellierungspraxis extrem anspruchsvoll, ist bei vielen übergeordneten Fragen eine Untergliederung in effektive Teilschritte doch alles andere als klar. Eine Vorstrukturierung auf dem Reißbrett ist nur in Einzelfällen möglich (wie im Fall der Sprachwissenschaft mit ihrer etablierten Ebenenstruktur der Sprachbetrachtung möglich ist, die auch die computerlinguistische Modulstruktur prägt, selbst wenn bewusst klassische Teilschritte kombiniert werden).
Für alle offenen Fragen der Modularisierung bietet die komputationelle Modellierung und die Verwendung von digitalen Arbeitsumgebungen Potenziale, die noch lange nicht ausgeschöpft sind: alternative Modularisierungen können exploriert und gegeneinander abgewogen werden. Der CRETA-Ansatz legt diese Exploration in die interdisziplinären Verantwortung: statt auf dem Reißbrett die plausibelste Untergliederung einer Projekt-Problematik festzuhalten, Softwarelösungen anhand dieser Spezifikation umzusetzen und nach zwei Jahren Entwicklung auf die inhaltliche Fragestellung anzuwenden, findet ein Dialog zwischen komputationellen Modellierungsexpertinnen und –experten und Fachwissenschaftlerinnen und –wissenschaftlern unterschiedlicher Disziplinen statt.
Überlegungen aus der fachspezifischen Kultur der Fragestellung müssen herangezogen werden, um eine geeignete Einbindung eines technisch übertragbaren Teilmodells in den Erkenntnisprozess und seine methodenkritische Reflexion zu gewährleisten. Gleichzeitig fleißen aus den informatischen Disziplinen Überlegungen zur formalen Adäquatheit möglicher Modellklassen, Erfahrungswerte aus der zu erwartenden Qualität, sowie Möglichkeiten einer Visualisierung und explorativen Ergebnispräsentation ein, um die wechselseitige Optimierung von Modellierungskomponenten zu unterstützen.
Konkret stellt sich das Vorgehen bei der Modellierung folgendermaßen dar: Im multidisziplinären Dialog im Rahmen von Werkstattklausuren werden für geistes- und sozialwissenschaftliche Fragestellungen mit Bezug zu ausgewählten digitalen Ressourcensammlungen
Die angesprochenen methodischen Desiderate eines transparenten Zugangs zu den Analyse-Teilergebnissen und der Adaptierbarkeit von analytischen Teilmodellen haben wir exemplarisch anhand mehrerer Erweiterungsszenarien des Relationsextraktionsmodells aus Blessing und Kuhn (2014) umgesetzt: Über die ursprüngliche Zielrelation (Emigrationsbewegungen, die in Kurzbiographien textuell beschrieben werden) können andere Relationen interaktiv trainiert werden. Eine Erweiterung des Korpusbestands um Texte aus weiteren Quellen wurde vorgenommen, einschließlich eines Wechsels der Sprache (Übertragung des Teilmodells als Erweiterung einer deutschen Analysekette auf eine französische). Eine analoge Adaptionsplattform wurde für Zeitungstexte erstellt, die in politikwissenschaftlichen Studien zum öffentlichen Diskurs analysiert werden.
Fallstudien zum Einsatz der resultierenden Analysekette zeigen, dass eine kritische Betrachtung der übertragenen Teilmodelle vor allem durch den Wechsel des Blickwinkels auf aggregierte Daten mit einer Verlinkung von Einzelinstanzen unterstützt werden: Textuelle Einzelinstanzen eines Relationstyps (z. B. Emigration einer Person X aus dem Land A in ein Land B) werden aggregiert und das Aggregationsergebnis kann beispielsweise geographisch visualisiert werden.
Das interaktive Springen zwischen unterschiedlichen Dimensionen der Aggregation bzw. zwischen aggregierter Sicht und Einzelinstanzen erlaubt es, Datenpunkte gezielt unter die Lupe zu nehmen, die von allgemeinen Tendenzen in bestimmter Weise abweichen. Für solche Beobachtungen ist zu klären, ob es sich (a) um einen aus bekannten Zusammenhängen erklärbaren, (b) einen neuartigen, validen Effekt oder (c) um einen technisch erklärbaren Scheineffekt handelt, der durch eine methodische Verbesserung eliminiert werden könnte. Ein Beispiel ist die fehlerhafte Klassifikation von UN-Resolution 1261 und 1973 in Zeitungsartikeln als Datumsangaben. Bei der Visualisierung der Extraktionsergebnisse auf einem Zeitstrahl fällt ein unerwartetes Muster beim Jahr 1261 auf (während Scheineffekte zum Jahr 1973 möglicherweise zunächst unerkannt bleiben). Die Fallstudien unterstützen die These, dass interaktive Nachforschungen und ein adaptierbares Instrumentarium gerade bei nicht perfekten Analysekomponenten die kritische Distanz zum Modellinventar unterstützen.