Auch in Zeiten von „Big Data“ haben relativ kleine, auf eine spezifische Fragestellung hin zugeschnittene und aufbereitete Korpora ihre Bedeutung. In diesem Beitrag beschreiben wir die Aufbereitung eines solchen Korpus für die nachhaltige Langzeitarchivierung und skizzieren die sich daraus ergebenden Möglichkeiten zur explorativen Analyse.
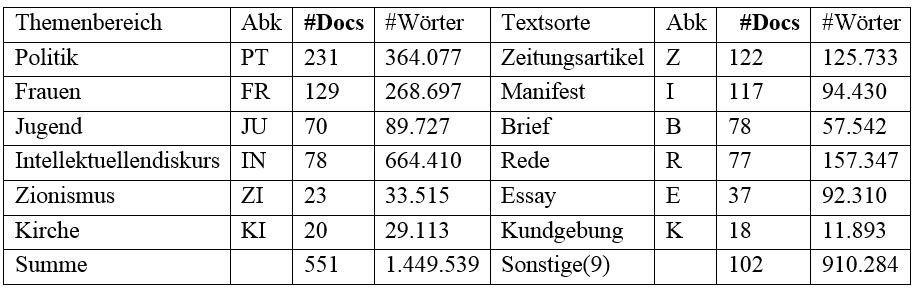
Das Korpus „Diskurs in der Weimarer Republik“ (DWR) wurde im Rahmen des Projektes „Demokratiediskurs 1918-1925“ (Kämper 2014) zur Dokumentation und Analyse des sprachlichen Wandels im Umbruch von der Monarchie zur Demokratie erstellt. Es umfasst 779 Dokumente im Zeitraum von 1912 bis 1933, davon 641 zwischen 1918 und 1925. 551 Dokumente sind (u. a.) nach Themenbereich und Textsorte klassifiziert (s. Tabelle 1).
Tab. 1: Themenbereiche und Auswahl an Textsorten im DWR
Ursprünglich wurde das Korpus im Rich-Text-Format (RTF) bzw. MS-Office (DOC) erstellt, und die Metadaten in einer Oracle-Datenbank verwaltet. Im Rahmen des LIS-Projektes „Zentrum für germanistische Forschungsprimärdaten“ 1 wurde das Korpus für die Langzeitarchivierung aufbereitet. Im Einzelnen wurden folgende Schritte durchgeführt:
Das aufbereitete Korpus 2 ist im Langzeitarchiv des IDS 3 (Fankhauser et al. 2013) abgelegt.
Zur Exploration sprachlicher Variation im Korpus wurde das Korpus zudem für ein am Institut für Deutsche Sprache entwickeltes System zur kontrastiven Visualisierung von Korpora (Fankhauser et al. 2014a, 2014b) aufbereitet.
Dafür wurde das Korpus an Hand der Metadaten für Themenbereiche und Textsorten in Teilkorpora aufgeteilt, und für die einzelnen Teilkorpora Frequenzlisten aller Wörter (ohne Lemmatisierung oder Stopwortausschluss) erstellt. Diese Frequenzlisten, repräsentiert als multinomiale Verteilungen über das Vokabular, werden mit Hilfe der Kullback-Leibler Divergenz verglichen. Auf dieser Basis wird die Distanz zwischen Teilkorpora in Form von Heatmaps visualisiert, und der Beitrag einzelner Wörter zu der jeweiligen Distanz mit Hilfe von Wortwolken.
Zur Exploration sprachlicher Variation im Korpus wurde das Korpus zudem für ein am Institut für Deutsche Sprache entwickeltes System zur kontrastiven Visualisierung von Korpora (Fankhauser et al. 2014a, 2014b) aufbereitet.
Dafür wurde das Korpus an Hand der Metadaten für Themenbereiche und Textsorten in Teilkorpora aufgeteilt, und für die einzelnen Teilkorpora Frequenzlisten aller Wörter (ohne Lemmatisierung oder Stopwortausschluss) erstellt. Diese Frequenzlisten, repräsentiert als multinomiale Verteilungen über das Vokabular, werden mit Hilfe der Kullback-Leibler Divergenz verglichen. Auf dieser Basis wird die Distanz zwischen Teilkorpora in Form von Heatmaps visualisiert, und der Beitrag einzelner Wörter zu der jeweiligen Distanz mit Hilfe von Wortwolken.
Abbildung 1 zeigt die Distanz zwischen Themenbereichen sowie zwischen Textsorten innerhalb eines Themenbereichs (grün für geringe, purpur für große Distanz). Es wird deutlich, dass der Themenbereich Kirche (KI) sich am deutlichsten von den anderen Themenbereichen abhebt. Innerhalb der Themenbereiche zeigt sich, dass die Textsorten - soweit für einen Themenbereich mit Dokumenten belegt - im Themenbereich Frauen deutlich stärker ausdifferenziert sind als im Themenbereich Politik. Inbesondere die Textsorten Stellungnahme (S) und Kundgebung (K) heben sich deutlicher von den anderen Textsorten ab als im Themenbereich Politik.
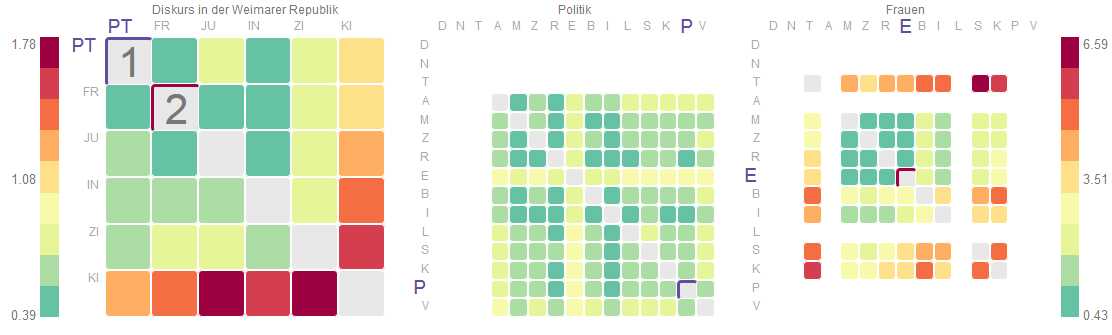
Abb. 1: Heatmaps für den Vergleich von Themenbereichen (links) und Textsorten innerhalb eines Themenbereichs ( Politik: mitte, Frauen: rechts).
Abbildung 2 zeigt den Beitrag einzelner Wörter zu der Distanz zwischen Teilkorpora in Form von Wortwolken. Groß dargestellte Wörter sind hierbei besonders typisch für ein Teilkorpus, die Farbe korrespondiert mit der relativen Häufigkeit eines Wortes im Teilkorpus (blau für selten, purpur für häufig). Die Wortwolke links vergleicht Frauen mit dem restlichen Korpus. Sie wird sowohl auf begrifflicher Ebene ( Frau/Mann) als auch auf grammatischer Ebene ( die, ihre, sie, …) vom allgemeinen Diskursgegenstand Frauen dominiert. Die Wortwolke in der Mitte zeigt die typischen Wörter von Zeitungsartikeln im Vergleich zu Essays innerhalb des Themenbereichs Frauen, die Wortwolke rechts typische Wörter im umgekehrten Vergleich. Hier wird deutlich, dass Zeitungsartikel sich im wesentlichen um die politisch/öffentliche Stellung der Frau drehen ( Wahlrecht, Frauenstimmrecht, politische) und Essays um die private Welt der Frau ( Beziehung, Moral, Erotik). Ein sehr deutlicher Unterschied zeigt sich auch im Numerus von Frau: Plural in Zeitungsartikeln und Singular in Essays.

Abb. 2: Wortwolken für die typischen Wörter des Themenbereichs Frauen im Vergleich mit dem restlichen Korpus (links) und in den Textsorten Zeitungsartikel vs. Essay im Themenbereich Frauen (mitte und rechts).
Dieser kurze explorative Überblick kann natürlich nur einen kursorischen Eindruck über Inhalt und Vielfalt des Korpus geben. Technisch wurde er erst möglich durch die konsequente Kuration der Metadaten und Daten an Hand der generellen Richtlinien der CLARIN Infrastruktur.